
In insurance, your most valuable insights are often trapped inside scanned forms, handwritten claims, or lengthy PDFs. Without the right insurance data extraction tools, that critical information stays hidden, slowing down claims, underwriting, and every process in between.
And the worst part? It’s rarely a system failure that causes delays. It’s stuff like an unread email, a missing tag on a policy document, or a file that never made it into the workflow. When even one document goes untouched, the entire operation can grind to a halt, costing time, trust, and money.
These slowdowns aren't anomalies—they're the norm. And while the impact might appear trivial in isolation, across a large operation, the effect compounds. Delayed underwriting decisions, missed claims deadlines, compliance breaches, or poor customer experiences all trace back to the same issue: buried data.
Most insurers have digitized their documents. But digitization isn’t enough. A digitized PDF still has to be read, interpreted, and entered manually. The real transformation begins when digitized data becomes usable data. That’s where insurance data extraction plays a critical role. Read on to know what it is, why it matters, and how to spot the right tool for a seamless workflow.
Why Insurance Data Extraction is Challenging & What to Do About It?
Insurance workflows generate a flood of data every day.
“80% of all insurance data lies trapped in everyday correspondence, but AI, used right, can provide easy, efficient access.”
Most data comes in unstructured formats: scanned images, third-party reports, handwritten forms, emails, and spreadsheets. These documents are essential to underwriting, claims, policy servicing, and regulatory compliance, but traditional systems can't process them without human intervention.
Even if your teams digitize everything, they still can’t use what they can’t extract.
And that’s the hidden cost of manual insurance tracking:
- Underwriting delays: Risk evaluations stalled because medical histories are buried in scanned forms.
- Claims leakage: Missed discrepancies or double-billing due to human oversight.
- Audit stress: Compliance teams spend weeks preparing for a regulator’s document request.
- Loss of loyalty: Customers drop after slow onboarding or payout friction.
According to McKinsey, insurance firms that integrate automation and AI into core processes can cut operational costs by up to 40%. Still, that level of efficiency is only possible if the foundational data is accessible, which is exactly what intelligent document processing for insurance data extraction delivers.

What is Insurance Data Extraction?
Insurance data extraction is the automated process of identifying, interpreting, and organising relevant information from insurance documents and for teams handling ACORD 130 submissions, AI data extraction for ACORD 130 and insurance submission forms is where those efficiency gains are most tangible. A critical factor when evaluating insurance data extraction capabilities in vendors. It’s the step that transforms unreadable files into structured, usable insights that fuel workflows.
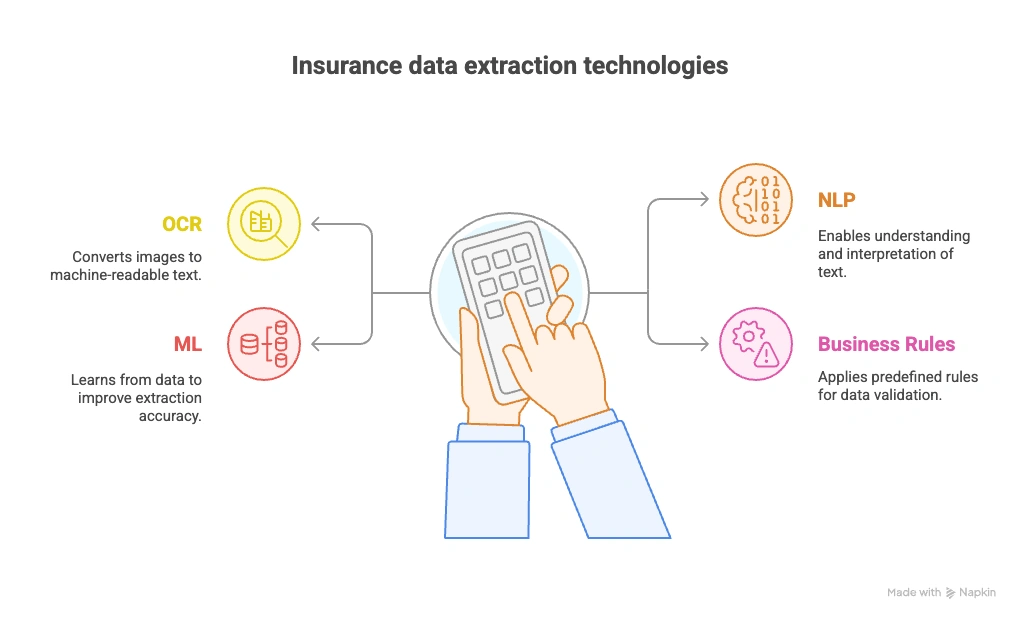
This process typically involves technologies like:
- Optical Character Recognition (OCR): Converts printed or scanned documents (like PDFs or faxes) into machine-readable text, enabling digital systems to access information locked in physical forms.
- Natural Language Processing (NLP): Understands the meaning and intent behind the words—helpful for interpreting descriptions of loss, identifying entities (e.g., names, dates), and extracting context-rich information.
- Machine Learning (ML): Learns from past document layouts and patterns to improve accuracy over time, even with messy or inconsistent document formats.
- Business Rules Engines: Apply industry-specific logic (such as validating coverage amounts or checking policy dates) to automatically flag inconsistencies and standardize the extracted data.
These capabilities form the backbone of Intelligent Document Processing (IDP) platforms tailored for insurance use cases.
Core Document Types Extracted in Insurance

- Claims Documents – These include First Notice of Loss (FNOL) forms, damage assessments, repair invoices, and loss statements submitted during the claims process.
- Policy Documents – Key documents like declarations pages, endorsements, and renewal papers that define coverage terms and conditions.
- Medical & Police Reports – Used in personal injury or liability claims; they contain complex narrative data that must be interpreted carefully.
- Adjuster & Appraisal Notes – Often handwritten or typed field reports detailing property inspections or damage evaluations.
- Flood Certificates & Risk Reports – Specialty forms used to verify high-risk properties, often requiring external data sources for validation.
- ACORD Forms (e.g., 125, 127) – Standardized forms used by brokers and agents to submit policy or risk information to carriers.
- Emails and Attachments – Critical details often reside in the body of emails or attached PDFs, Excel files, or scanned forms, making them easy to miss in manual workflows.
Each of these documents can vary in structure, contain freeform text, or mix visual elements like tables and images. Which is why automated extraction is preferred over manual insurance data extraction. Let’s compare.
Comparing Manual vs. Automated Insurance Data Extraction Methods
A side-by-side comparison of what your operations look like today, and what they could be with automated Insurance Data Extraction.
“The cost of manual rework in insurance averages $25 per claim, which is the financial burden of a manual process.”
Why Insurance Data Extraction Matters in 2025?
With rising customer expectations, competitive pressure, and regulatory oversight, insurance companies can’t afford manual inefficiencies. Yet, in many operations, staff still spend hours reviewing forms, cross-checking spreadsheets, or copying details between systems.
Automated data extraction eliminates those frictions. It accelerates underwriting decisions by surfacing key risk indicators instantly. It speeds up claims processing by extracting and verifying damage assessments, invoices, and statements. It strengthens compliance by enabling searchable audit trails and consistent redaction.
More importantly, it allows insurers to shift from reactive workflows to proactive, insight-led operations. When data flows seamlessly, decisions happen faster, and customer trust builds naturally.
It also accelerates back-office functions like invoice data capture—automating the extraction of amounts, vendor details, and line items from invoices, making payouts faster and accounting cleaner.
The $1 Trillion Opportunity
According to McKinsey, insurance carriers that embrace AI and automation are poised to capture a portion of the $1 trillion in potential annual savings by 2030. Which is why on-the-go custom model creation for insurance document data extraction lets teams prove that accessibility on their own documents before signing anything
And that’s not just about cost-cutting—it’s about smarter pricing, faster claims resolution, and scalable growth.
Automation is not about reducing headcount. It’s about giving your teams the data they need—instantly—to make better decisions.
Why CEOs, CFOs & COOs Should Care about Insurance Data Extraction?
Insurance leaders today face pressure to cut costs, move faster, and reduce risk — all while improving the customer experience. Manual data entry and slow document processing stand in the way. Intelligent data extraction solves this by automating the most time-consuming, error-prone parts of the workflow. From reducing claim cycle costs to improving audit readiness and fraud detection, here’s why the C-suite should care.
1. Operational Cost Reduction
Manual document triage and data entry eat up 30–50% of claim lifecycle costs. Automation cuts this dramatically, and can reduce headcount needs too.

2. Faster Time to Decision
First Notice of Loss (FNOL) in minutes rather than hours or days. With real-time extraction and validation, cases get routed to adjusters or underwriters instantly.
3. Risk Accuracy & Fraud Detection
With contextual AI models, automated data extraction can flag overcharges, suspicious patterns, and mismatches, reducing fraud exposure.
4. Compliance & Audit Readiness
Auditors want structured trails, not folders. Automated extraction logs every datapoint, source, timestamp, and reviewer, simplifying audits and data lineage demands.
5. Better Customer Experience
Go from cumbersome back-and-forth to streamlined service. Chatbots and self‑service tools powered by AI can resolve queries instantly, using extracted data.
Why Legacy Systems Can’t Handle Insurance Data Extraction Today?
Traditional OCR or IDP tools weren’t built for the complexity of insurance workflows. Here’s what they miss:
- Layout Variance: One FNOL form differs drastically from another.
- Mixed Media: Images, tables, signatures, text blobs—all in one file.
- Language & Jargon: Adjuster notes are messy, narrative, and full of shorthand.
- Contextual Triggers: Identifying red flags like “fire loss within 30 days of policy start.”
Without advanced AI, especially LLMs fine-tuned for insurance, your system is just reading pixels, not understanding risk.
C-Suite Benefits: Where Insurance Data Extraction Delivers Real Impact
Claims Transformation
Speed isn’t just a goal—it’s a competitive edge. Intelligent data extraction processes FNOL forms, invoices, and third-party assessments in seconds, not hours. It flags missing docs, surfaces red flags, and auto-routes clean data to the right team.
✅ Faster claims resolution
✅ Lower loss adjustment expenses
✅ Improved first-contact time
Underwriting Intelligence
Underwriters don’t need more data—they need better access to it. Automated extraction pulls risk signals from inspections, appraisals, loss runs, and medical records, validating them instantly.
✅ Sharper risk scoring models
✅ Quicker quote-to-bind cycles
✅ Reduced manual review time
Compliance & Audit Readiness
Audits shouldn’t throw your team into chaos. With extraction built for governance, every field is auto-tagged, redacted where needed, and backed by full data lineage and timestamps.
✅ Instant audit readiness
✅ Fewer compliance errors
✅ Automated regulatory mapping (TRIA, CCPA, GDPR)
AI-Driven Operations
Data is fuel for modern insurance operations. Clean, structured inputs power fraud detection, policy lapse prediction, and even claims triage through AI agents.
✅ More decisions, fewer escalations
✅ Fewer false positives in fraud detection
✅ Scalable automation across business lines
Bringing It All Together: A Step‑by‑Step Path to Scale
- Identify the pain points: Start with document-heavy workflows across claims, underwriting, and billing.
- Prioritize pilot-ready areas: Claims intake and policy issuance deliver the fastest returns.
- Build the ROI case: A 50% reduction in data entry costs on a $10M workflow means $5M in savings.
- Choose the right partner: Work with a vendor like Infrrd, known for strong SLAs and proven deployments.
- Launch a pilot: Process 500–1,000 documents from real channels like inboxes or vendor portals.
- Track what matters: Measure accuracy, turnaround time, user satisfaction, and error reduction.
- Scale with confidence: Expand to more lines of business, document types, and geographies.
- Turn data into intelligence: Use extracted data to surface trends, improve pricing, and catch fraud before it happens.
6 Things to Check in an Insurance Data Extraction Platform
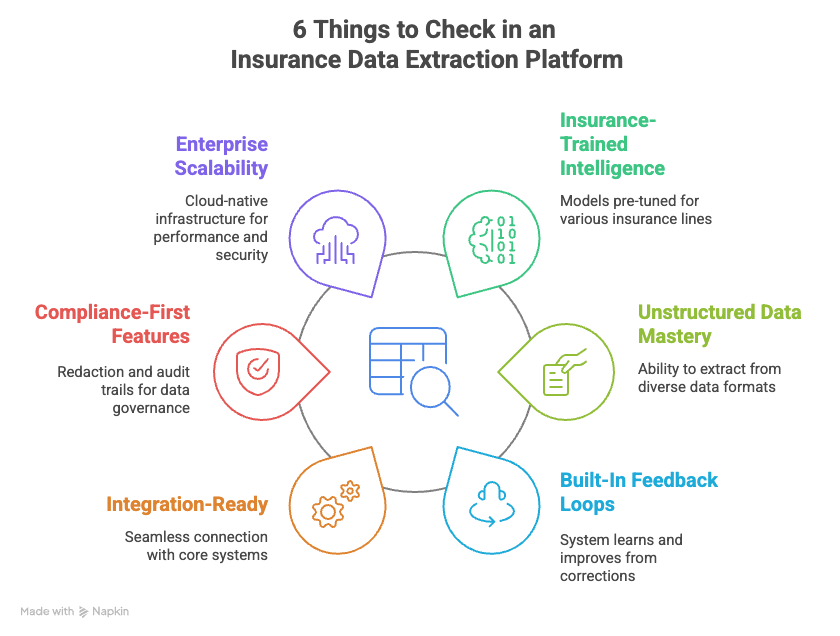
- Insurance-trained intelligence: Models pre-tuned for P&C, Life, Health, and Specialty lines
- Unstructured data mastery: Extract from tables, handwriting, scanned forms, and irregular layouts
- Built-in feedback loops: Learns and improves from corrections automatically
- Integration-ready: Connects seamlessly with core systems like Guidewire and Duck Creek
- Compliance-first features: Redaction, audit trails, and robust data governance baked in
- Enterprise scalability: Cloud-native infrastructure that meets performance and security needs
Why Infrrd is the go-to choice for Insurance Data Extraction?
Infrrd is purpose-built for the complexity of insurance workflows. Whether you’re processing scanned FNOL forms, handwritten appraisals, or PDF bundles of COIs and endorsements, Infrrd adapts and delivers.
Domain-Specific Intelligence
- Pre-trained models for P&C, Life, Health, and Specialty lines
- ACORD, ISO, loss run, and binder formats handled natively
Zero-Template Approach
- Infrrd doesn't rely on static templates
- Layout-agnostic extraction adapts to every carrier, every form
See it in action
Enterprise-Scale Efficiency
- Processes over 1 million insurance documents/month
- Prioritizes SLAs with intelligent queueing
- Supports real-time routing into claims and policy systems
The best proof? The ones who use it at scale

Even Analysts Agree: Infrrd Leads the Pack
Back your decision with Everest Group’s latest analyst assessment. See how Infrrd stacks up—and why buyers trust us to automate what others can’t.
Read the analyst report.

Future Trends to Watch for Insurance Data Extraction
Zero-shot extraction
Extract data from unseen document formats without retraining.
- Useful for handling new claim templates or policy documents instantly.
Multi-document chaining
Connect data across multiple documents to build a unified view.
- Think of linking claim forms, emails, and police reports to evaluate risk faster.
Conversational review
Use GenAI to “chat” with claims files.
- Ask: “What was the insured value?” and get a direct answer.
Context-aware compliance tagging
Auto-flag PII or sensitive data based on context.
- Helps ensure GDPR/HIPAA compliance during data processing.
In a Nutshell
If your underwriting, claims, and compliance teams are still manually reading through PDFs and typing values into systems, you're not running lean, you’re bleeding money.
Insurance is about speed, accuracy, and trust. Intelligent data extraction powers all three.
It’s time to stop letting documents slow you down. Insurance data extraction is not IT’s problem. It’s a C-suite opportunity.
And the leaders who understand this? They’re already processing faster, selling smarter, and winning customer trust.
Want to see how? Let Infrrd show you. Book a demo.

Bhavika Bhatia is a Product Copywriter at Infrrd who blends curiosity with clarity to craft content that makes complex tech feel simple and human. With a background in philosophy and a knack for storytelling, she turns big ideas into meaningful narratives. Outside of work, you’ll find her chasing the perfect café corner, binge-watching a new series, or lost in a book that sparks more questions than answers





