
If data is the new oil, most businesses are still drilling with a shovel.
Despite years of digitization and massive investments in analytics platforms, a majority of companies are only scratching the surface of what their data can do. The culprit? Unstructured information—and the lack of automated data extraction to make sense of it at scale.
Unstructured data encompasses a wide range of information, including contracts, scanned documents, emails, voice notes, handwritten forms, and PDFs. According to a Forbes report, nearly 80% of enterprise data remains unstructured and, as a result, largely unused.
But volume isn’t the only issue. The IDC projects that the global datasphere will balloon to 175 zettabytes by 2025, and about 80% of that data will be unstructured. Shockingly, up to 90% of this information will never be analyzed, locked away in formats that traditional systems simply can’t interpret.
Most businesses focus their analytics on clean, structured datasets, like CRM exports, sales reports, or ERP entries. However, a Deloitte survey found that only 18% of organizations actively leverage unstructured data sources, such as customer emails, call transcripts, product images, or scanned documents. That leaves a wide gap between what companies know and what they could know.
This is exactly where automated data extraction comes in.
In this blog, we’ll explore how modern enterprises are using automated data extraction to convert document overload into business intelligence — including how structured data extraction methods make that transformation reliable at scale. Before we go in. First things first.
What is Data Extraction in 2025?
For years, data extraction simply meant pulling text from a document or scanning a paper record into a system. But in 2025, that definition no longer holds up.
Modern data extraction is intelligent, automated, and context-aware. It’s the process of locating, interpreting, and converting unstructured or semi-structured content like PDFs, scanned forms, emails, or images into structured, usable data that can fuel analytics, automation, and operations.
When powered by AI, this becomes automated data extraction, where machines don’t just read documents, they understand them. They interpret intent, identify relationships between fields, and extract relevant information with minimal human intervention.
Infrrd defines automated data extraction as the ability to process raw, complex documents at scale and output decision-ready data. It's a leap beyond OCR—blending machine learning, natural language processing (NLP), and rule-based validation into a unified process.
Unlike traditional tools, modern extraction platforms can:
- Grasp document context and layout using NLP
- Segment sections and detect field types dynamically
- Extract key-value pairs and tabular data accurately
- Validate fields against predefined logic or external data sources
Curious how it looks in practice?
Watch: How Automated Data Extraction Works with Infrrd
Types of Data You’ll Encounter in Data Extraction
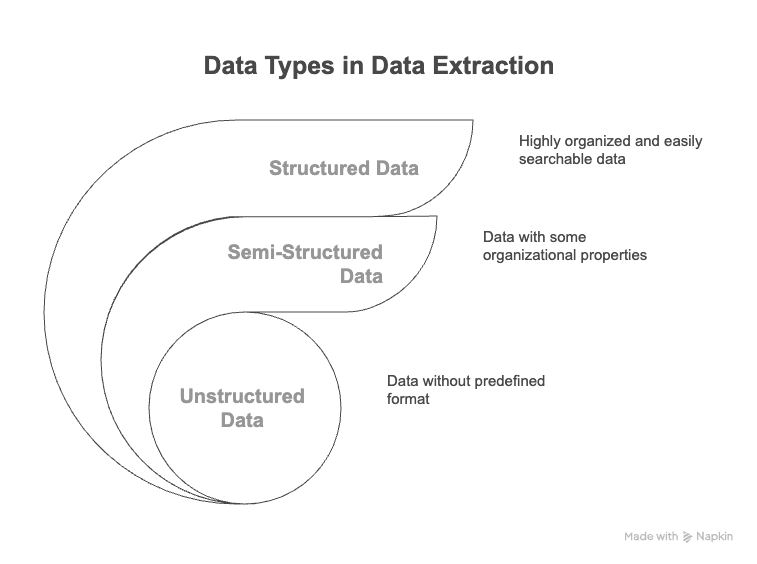
Before diving into automation strategies, it’s worth recognizing the three core types of data businesses deal with—because not all data behaves the same.
1. Structured Data
This is the neat and tidy kind—think rows and columns. It lives in databases and spreadsheets, where every field has a label and a consistent format.
Examples: Sales reports, ERP tables, CRM exports
Best fit for: Rule-based automation, direct integrations
Extraction complexity: Low — format is consistent and predictable
2. Semi-Structured Data
This one lives in the gray zone. It’s not organized like a spreadsheet, but it still carries cues—tags, templates, or markers—that help make sense of it.
Examples: Email templates, XML/JSON files, system logs
Best fit for: NLP-driven parsing, template learning
Extraction complexity: Moderate — contains structure but varies by source
3. Unstructured Data
Here’s the wild west. No clear layout. No defined structure. But often, this is where the most valuable insights hide—if you can extract them.
Examples: Contracts, scanned forms, handwritten notes, engineering diagrams
Best fit for: AI-based IDP with OCR, ML, and deep learning
Extraction complexity: High — data is irregular, varied, and context-dependent
Modern extraction tools like Infrrd’s AI-powered platform are built to tackle all three types with context-aware precision, ensuring no valuable data slips through the cracks. Explore Infrrd’s data extraction capabilities.
The Unstructured Elephant in the Room
Unstructured data poses real challenges to productivity and compliance. Industries from finance to healthcare deal with countless documents that contain critical data, but these remain largely inaccessible due to format, volume, or complexity.
For example, mortgage lenders spend hours reviewing income documents. Insurers must manually sift through medical reports. Manufacturing companies struggle with engineering drawings filled with specs and tolerances. Without automated data extraction, these workflows are slow, error-prone, and expensive.
Infrrd for Engineering Drawings helps automate the reading of blueprints, technical diagrams, and P&ID files—accelerating part identification and procurement.
Read this to know how it works in the real world: Automate Data Extraction from Complex Documents Easily.
Real ROI of Automated Data Extraction
The business value of automated data extraction extends far beyond faster paperwork. It enables a more agile, accurate, and cost-effective organization. Here’s how it adds up:
- Productivity boost: Employees no longer need to copy-paste data across systems or cross-check spreadsheets manually.
- Accuracy improvements: Machine learning models trained on your data ensure consistent field mapping and extraction, achieving 95–99% accuracy in production.
- Cost savings: By automating repetitive data tasks, companies can reallocate headcount to higher-value roles and cut processing costs by up to 70%.
- Compliance readiness: Extracted data is tagged, time-stamped, and auditable—helping you stay ready for internal and external reviews.
With Infrrd’s mortgage automation platform, for instance, lenders have achieved real-time income verification, faster loan processing, and higher data integrity across the board.
Want the numbers? Try our ROI Calculator
The Technology Stack Behind Automated Data Extraction
Today’s automated data extraction is driven by an integrated stack of advanced technologies, each playing a key role in transforming unstructured documents into structured, actionable data:
- Optical Character Recognition (OCR)
Modern OCR doesn’t just extract text—it handles low-resolution scans, multi-column layouts, and even handwritten inputs with impressive accuracy. It’s the foundation for digitizing any visual document. - Natural Language Processing (NLP)
NLP brings understanding to the data. It interprets meaning, detects intent, and extracts context—whether from dense contracts, customer emails, or annual reports. - Machine Learning (ML)
ML models continuously improve by learning from real documents. They detect field types, correct anomalies, and adapt to variations in formatting, language, and layout. - Intelligent Document Processing (IDP)
IDP ties it all together. It’s a unified framework that combines OCR, NLP, ML, and workflow automation, managing the full lifecycle of document handling from ingestion to validation.
Infrrd’s IDP platform leverages this full tech stack to help enterprises process millions of documents with speed, security, and near-human precision.
Who Needs Automated Data Extraction the Most?
Not every business struggles with data in the same way. But for industries drowning in documents—mortgage files, medical records, insurance claims, contracts, and technical drawings—manual processing is a daily bottleneck.
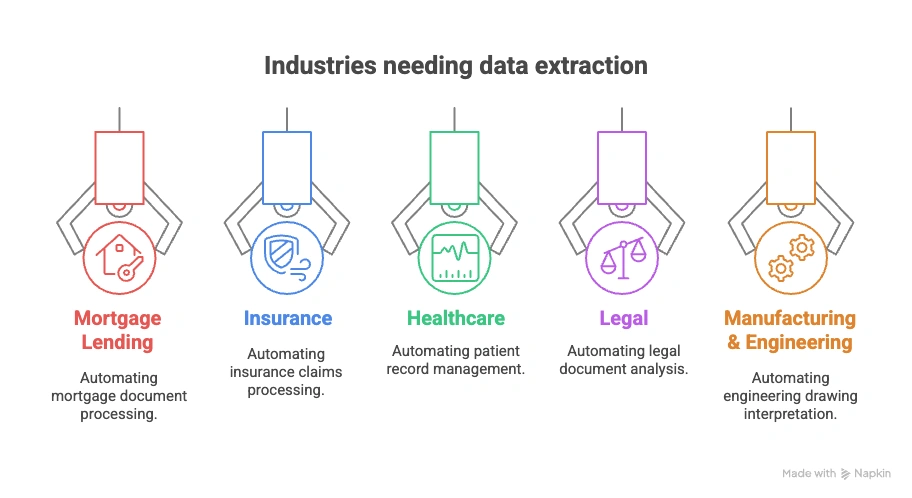
These are the sectors where automated data extraction is a necessity.
1. Mortgage Lending
Lenders handle hundreds of pages per loan file, each packed with income statements, disclosures, and borrower documents. Automated data extraction accelerates underwriting, reduces manual errors, and ensures compliance across investor guidelines.
2. Insurance
Claims teams process diverse, often messy documentation—handwritten forms, medical reports, and incident photos. Automated data extraction identifies key fields, flags inconsistencies, and accelerates triage and adjudication. The result? Faster claims and better customer trust.
3. Healthcare
From clinical notes and prescriptions to diagnostic reports, healthcare workflows rely on data trapped in unstructured formats. Automated extracts relevant codes, patient histories, and medications to improve billing accuracy and care coordination—all while staying HIPAA-compliant.
4. Legal
Contracts and legal documents are dense and repetitive. Automated data extraction helps legal teams identify renewal terms, obligations, and risk clauses instantly, reducing manual review time and ensuring nothing slips through the cracks.
5. Manufacturing & Engineering
Blueprints, spec sheets, and part drawings contain critical dimensions, tolerances, and identifiers. Infrrd’s engineering drawing extraction turns technical diagrams into structured, searchable data, streamlining procurement and speeding up time-to-quote.
How to Get Started: A Roadmap to Automated Data Extraction
Implementing automated data extraction doesn’t have to be overwhelming. With a structured approach, you can go from inefficiency to intelligent automation much faster than you think. Here’s a practical, five-step roadmap to help your organization make a confident transition:
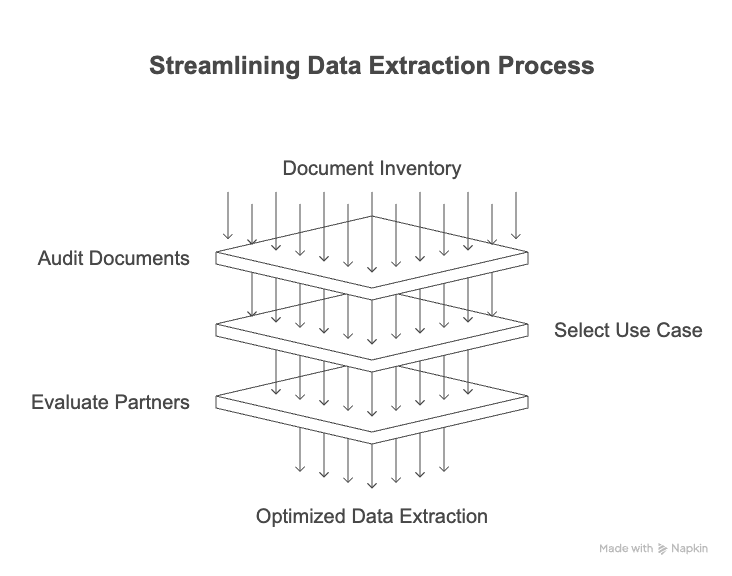
1. Audit Your Document Inventory
Start by understanding the scale and complexity of your existing document workflows. Which business processes are document-heavy, slow, and error-prone? Common hotspots include:
- Loan onboarding and mortgage income calculations
- Invoice processing and vendor management
- Claims intake and adjudication in insurance
- Contract analysis and compliance reviews
- Engineering drawings and procurement approvals
Ask yourself:
- Are we manually reviewing repetitive formats?
- Are there delays due to missing or misfiled data?
- Which teams are spending the most time handling documents?
A clear audit reveals where the inefficiencies lie—and where automation will drive the most value.
2. Select a High-Impact Use Case
Not all use cases are created equal. Focus on a process that is:
- Repetitive and high-volume
- Clearly measurable (time spent, error rate, cost per document)
- Business-critical but currently bottlenecked
For example:
- In mortgage lending, start with automating income document extraction (W2s, paystubs, tax returns).
- In finance, automate invoice capture and validation for quicker accounts payable cycles.
- In insurance, try extracting key fields from first notice of loss (FNOL) documents.
Choosing a focused, high-ROI use case helps you prove value quickly and build momentum internally.
3. Evaluate Technology Partners
The right platform should solve your real-world challenges. When comparing vendors, consider:
- Document diversity: Can the platform handle structured, semi-structured, and unstructured formats, including scanned documents, handwritten forms, and images?
Accuracy: Does it consistently deliver 95% + field-level accuracy? Does it offer a human-in-the-loop model when needed? - Security & Compliance: Is the platform compliant with SOC 2, HIPAA, or GDPR as needed? Is data encrypted at rest and in transit?
- Ease of Integration: Does it plug into your existing tech stack—LOS, CRM, ERP, claims systems, or custom databases?
- Scalability: Can it handle increasing document volumes across geographies and departments?
Want to test it yourself? Infrrd offers Doc Studio, a self-serve tool that lets you upload your own documents and see how our extraction engine performs before committing to a full deployment.
Watch the magic unfold:
The Future is Conversational & Proactive Data Extraction
Until recently, document automation was mostly reactive. You uploaded a file, ran a batch job, and got structured data back. But that’s changing, quite fast.
The next wave of innovation is about interactive, intelligent automation. We’re entering an era where automated data extraction isn’t just about reading documents—it’s about understanding them, reasoning with them, and triggering the right action in real time.
Say suppose:
- You ask: “Summarize Q2 performance from all subsidiary reports.”
The system reads hundreds of dense PDFs, extracts KPIs, highlights red flags, and delivers a single summary slide with YoY trends—ready for your leadership review. - A supplier invoice lands in your inbox.
The platform detects that it exceeds your pre-approved limit, checks that the PO is missing, and sends a real-time alert to your finance controller before payment is triggered. - You update your ESG policy.
The system finds every contract with outdated compliance language, flags them for legal review, and auto-generates updated clauses—all while maintaining a full audit trail.
This is what we mean by proactive document intelligence. It’s automated data extraction that doesn’t just convert files—it reasons, reacts, and routes information across your business in real time.
Platforms like Infrrd’s Mortgage Ally AI Agent are pioneering this shift in the mortgage space. And this vision isn’t limited to mortgages. It’s coming to insurance claims, healthcare diagnostics, manufacturing workflows, and financial reporting.
The Goldmine You Already Own
Every business is sitting on a treasure trove of information. Contracts, forms, loan files, medical charts, engineering diagrams—these documents contain not just data, but insight. They tell you how your business runs, where it’s vulnerable, and where it can grow.
The problem isn’t that the data doesn’t exist. It’s that you can’t access it fast enough or trust it when you do. That’s where automated data extraction becomes transformational.
It’s the tool that turns unstructured documents into structured truth. It’s the foundation for everything downstream: faster approvals, smarter forecasting, better compliance, and smoother customer experiences.
It’s your shovel, your refinery, and your engine—wrapped in AI.
And the best part? You don’t need to reinvent your business to benefit. You just need to unlock what’s already there.
Whether it’s income data in a borrower’s application, risk language in a vendor agreement, or part specs in a blueprint, Infrrd helps you turn document overload into operational intelligence.
Talk to our team and see how Infrrd powers smarter, faster, more proactive operations, multiple documents at a time.

Bhavika Bhatia is a Product Copywriter at Infrrd who blends curiosity with clarity to craft content that makes complex tech feel simple and human. With a background in philosophy and a knack for storytelling, she turns big ideas into meaningful narratives. Outside of work, you’ll find her chasing the perfect café corner, binge-watching a new series, or lost in a book that sparks more questions than answers





