
Say you open a folder filled with 1,000 scanned invoices. Each document has vendor logos, disclaimers, and long blocks of text. But all you need are three details like Invoice Number, Invoice Date, and Total Amount.
If you rely on traditional OCR, the system will read every word on every page. Then, you’ll have to sift through all that raw text to find the information you need. That means more processing time, more manual effort, and more chances for errors.
Zonal OCR offers a smarter way. Instead of scanning an entire page, it focuses on predefined areas called zones and extracts only the fields that matter. This targeted approach makes Zonal OCR faster and more accurate for documents with predictable layouts.
Let’s take a deep dive into what Zonal OCR is, how it works, where it excels, and where it falls short. We’ll also take a closer look at why businesses are shifting to Intelligent Document Processing (IDP) and what that means for the future of automation.
Warum sprechen Unternehmen immer noch über zonale OCR?
Angenommen, Sie öffnen einen Ordner mit 1.000 gescannten Rechnungen. Jedes Dokument enthält Herstellerlogos, Haftungsausschlüsse und lange Textblöcke. Sie benötigen jedoch lediglich drei Angaben wie Rechnungsnummer, Rechnungsdatum und Gesamtbetrag.
Wenn du dich darauf verlässt herkömmliches OCR, das System liest jedes Wort auf jeder Seite. Dann müssen Sie den gesamten Rohtext durchsuchen, um die Informationen zu finden, die Sie benötigen. Das bedeutet mehr Verarbeitungszeit, mehr manuellen Aufwand und mehr Fehlerwahrscheinlichkeit.
Zonal OCR bietet eine intelligentere Methode. Anstatt eine ganze Seite zu scannen, konzentriert es sich auf vordefinierte Bereiche, die als Zonen bezeichnet werden, und extrahiert nur die Felder, die wichtig sind. Durch diesen gezielten Ansatz wird die zonale OCR für Dokumente mit vorhersehbaren Layouts schneller und genauer.
Schauen wir uns einmal genauer an, was Zonal OCR ist, wie es funktioniert, wo es sich auszeichnet und wo es zu kurz kommt. Wir werden uns auch genauer ansehen, warum Unternehmen auf Intelligent Document Processing (IDP) umsteigen und was das bedeutet Die Zukunft der Automatisierung.
Was ist eine zonale OCR?
Zonale OCR, auch als vorlagenbasierte OCR bezeichnet, liest nur Text aus vordefinierten Bereichen auf einer Seite. Diese Bereiche sind Bereiche das Sie anhand eines Beispieldokuments erstellen.
Stellen Sie sich vor, Sie haben jedes Mal eine Rechnung mit dem Gesamtbetrag, der in der unteren rechten Ecke aufgedruckt ist. Mit zonaler OCR können Sie ein Feld über diesem Bereich definieren und es mit „Insgesamt“ kennzeichnen. Ab diesem Zeitpunkt liest das System bei der Verarbeitung ähnlicher Rechnungen nur noch diesen Abschnitt.
Wie unterscheidet es sich von Ganzseiten-OCR
- Ganzseitige OCR scannt das gesamte Dokument. Es gibt den gesamten Text als Klartext oder als durchsuchbares PDF aus. Das bedeutet später mehr Aufräumarbeiten.
- Zonales OCR extrahiert nur bestimmte Felder. Die Daten liegen in strukturierten Formaten wie JSON, XML oder CSV vor und sind somit bereit für Automatisierungsworkflows.
Dieser Ansatz spart Zeit und reduziert Fehler, vorausgesetzt, die Layouts sind konsistent.
Warum zonales OCR immer noch wichtig ist
Warum verwenden Unternehmen immer noch zonale OCR, wenn es erweiterte Optionen wie IDP gibt? Die Antwort ist einfach: vorhersehbare Layouts.
Wenn Ihre Dokumente selten das Format ändern, kann Zonal OCR Geschwindigkeit und Genauigkeit zu geringeren Kosten bieten. Zu den Beispielen gehören:
- Stromrechnungen
- Bankschecks
- Standardisierte Steuerformulare
- Versandetiketten
Hier ist der Grund, warum zonale OCR in diesen Fällen gut funktioniert:
- Genauigkeit: Liest nur markierte Bereiche und vermeidet so Geräusche aus anderem Text.
- Geschwindigkeit: Verarbeitet kleine Abschnitte und reduziert so den Zeitaufwand pro Dokument.
- Strukturierte Ausgabe: Lange Textdateien müssen nicht analysiert werden. Die Felder sind beschriftet und bereit.
- Niedrigere Infrastrukturanforderungen: Einfachere Einrichtung im Vergleich zu fortschrittlichen KI-Systemen.
So funktioniert zonales OCR
Zonales OCR mag technisch klingen, aber der Arbeitsablauf ist ziemlich einfach. Es dreht sich um das Extrahieren von Text aus vordefinierten Bereichen (oder „Zonen“) eines Dokuments. So läuft der Prozess ab:
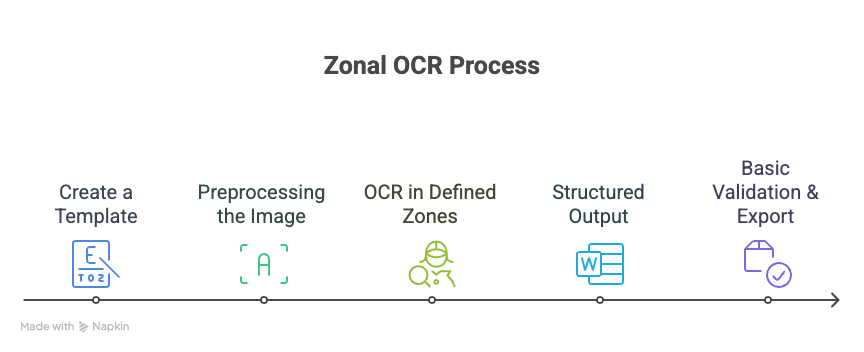
Schritt 1: Vorlage erstellen
Laden Sie zunächst ein Beispieldokument hoch, das das Standardlayout darstellt. Zeichnen Sie dann manuell Rechtecke um die Felder, die Sie erfassen möchten, wie Nummer der Rechnung, Name des Kunden, oder Fälliger Betrag. Weisen Sie jeder Zone Beschriftungen zu, damit das System weiß, welche Daten extrahiert werden müssen.
Diese Vorlage wird zur Grundlage für die Verarbeitung aller ähnlichen Dokumente.
Schritt 2: Vorverarbeitung des Bilds
Bevor OCR aktiviert wird, optimiert das System das gescannte Dokument, um die Texterkennung zu verbessern. Zu den üblichen Vorverarbeitungsaufgaben gehören:
- Entkippen: Begradigt geneigte Scans, um den Text richtig auszurichten.
- Geräuschreduzierung: Entfernt Markierungen, Flecken und Schatten, die die OCR verwirren könnten.
- Schwellenwert: Verbessert den Kontrast zwischen Text und Hintergrund für eine bessere Lesbarkeit.
Diese Schritte sind entscheidend für die Genauigkeit, insbesondere bei Scans mit geringer Qualität.
Schritt 3: OCR in definierten Zonen
Sobald die Vorverarbeitung abgeschlossen ist, konzentriert sich die OCR-Engine nur auf den vordefinierten Zonen. Alles, was außerhalb dieser Felder liegt, wird ignoriert, wodurch Verarbeitungszeit und Fehler reduziert werden.
Dieser selektive Ansatz eignet sich gut für strukturierte, wiederholbare Formulare.
Schritt 4: Strukturierte Ausgabe
Die extrahierten Daten werden den entsprechenden Feldbezeichnungen zugeordnet und in strukturierte Formate exportiert wie CSV, JSON, oder XML. Dies macht es einfach, die Daten in ERP-Systeme, CRMs oder andere nachgelagerte Anwendungen zu übertragen.
Schritt 5: Grundlegende Validierung und Export
Um häufige Fehler zu vermeiden, können Sie einfache Validierungsregeln anwenden, z. B.:
- „Feld muss numerisch sein“
- „Wert muss dem Datumsformat entsprechen (MM/TT/JJJJ)“
Nach der Validierung werden die bereinigten Daten zur Verarbeitung an Ihr Geschäftssystem gesendet.
Dieser Prozess funktioniert zwar effizient für einheitliche Dokumente, hat aber Probleme, wenn die Layouts auch nur geringfügig variieren. Aus diesem Grund stellen viele Unternehmen aus Gründen der Flexibilität und Skalierbarkeit auf Intelligent Document Processing (IDP) um.
Die Wissenschaft hinter zonaler OCR
Zonal OCR basiert auf klassischen OCR-Prinzipien. Untersuchungen zeigen zwei Hauptfaktoren auf, die für ihre Leistung verantwortlich sind:
- Segmentierung
- Das Dokument ist zur Analyse in kleinere Abschnitte unterteilt.
- Zu den Methoden gehören von oben nach unten (Aufteilen großer Blöcke in kleinere Zonen) und von unten nach oben (Gruppierung kleiner Elemente in größere Strukturen wie Wörter und Linien).
- Das Dokument ist zur Analyse in kleinere Abschnitte unterteilt.
- Vorverarbeitung
- Die Bildqualität wirkt sich auf die OCR-Genauigkeit aus. Schrägstellung, Rauschunterdrückung und Kontrastanpassungen sind für den Erfolg unerlässlich.
Diese Schritte stellen sicher, dass der Text innerhalb der Zonen sauber und für OCR-Engines leicht lesbar ist.
Primäre Anwendungsfälle von zonaler OCR
Zonale OCR ist am stärksten, wenn Sie mit Dokumenten arbeiten, die statische, vorhersehbare Layouts. Diese Dokumente verwenden in der Regel feste Positionen für Schlüsselfelder, wodurch eine vorlagenbasierte Extraktion durchführbar und effizient ist. Hier sind einige gängige Szenarien, in denen zonale OCR einen echten Mehrwert bietet:
1. Rechnungen und Quittungen
Für Anbieter oder Partner, die eine verwenden standardisiertes Rechnungsformat, Zonal OCR kann wichtige Details schnell erfassen wie:
- Nummer der Rechnung
- Datum der Ausgabe
- Gesamtbetrag
Anstatt Haftungsausschlüsse, Begriffe oder Fußnoten zu analysieren, konzentriert sich Zonal OCR auf die von Ihnen definierten Felder und beschleunigt so die Verarbeitung von Massenrechnungen.
2. Formulare für das Gesundheitswesen
Das medizinische Umfeld stützt sich immer noch stark auf strukturierte Formen wie Zulassungsformulare oder Versicherungsansprüche. Zonal OCR kann Folgendes genau abrufen:
- Patienten-ID
- Diagnosecodes (ICD-Codes)
- Aufnahme- und Entlassungstermine
Dieser selektive Ansatz reduziert die manuelle Dateneingabe und beschleunigt die Schadens- und Berichtsprozesse.
3. Kontoauszüge
Bei der Verarbeitung von wiederkehrenden Kontoauszugsformaten zeichnet sich Zonal OCR durch die Extraktion folgender Merkmale aus:
- Aktueller Saldo
- Informationen zum Kontoinhaber
- Zusammenfassung der Transaktionen
Durch das Ignorieren von Marketingbotschaften oder irrelevanten Hinweisen liefert es saubere, strukturierte Daten für Abstimmungs- oder Konformitätsprüfungen.
4. Überprüfung der ID
Ausweisdokumente wie Führerscheine oder Reisepässe sind stark strukturiert und eignen sich daher perfekt für zonales OCR. Zu den häufig extrahierten Details gehören:
- Vollständiger Name
- Datum der Geburt
- Nummer des Dokuments
Dies ist besonders nützlich für KYC (Kenne deinen Kunden) Prozesse im Bankwesen und Fintech.
5. Logistik- und Versanddokumente
In der Logistik standardisierter Papierkram wie Frachtbriefe oder Packzettel macht vorlagenbasiertes OCR praktisch. Zonale OCR kann Folgendes erfassen:
- Sendungsnummer
- Lieferadresse
- Angaben zum Transporteur
Dies gewährleistet eine schnellere Bearbeitung in Lagern oder bei der Zollabfertigung.
Vorteile von Zonal OCR
1. Hohe Genauigkeit bei festen Layouts
Zonale OCR funktioniert am besten, wenn Dokumente derselben Struktur oder Vorlage folgen. Da das System genau weiß, wo nach Informationen gesucht werden muss, bleibt die Fehlerrate im Vergleich zu Ganzseiten-OCR, bei der alles interpretiert werden muss, sehr niedrig.
2. Schneller als ganzseitige OCR
Anstatt die gesamte Seite zu scannen und zu analysieren, konzentriert sich die zonale OCR nur auf bestimmte Bereiche, in denen Daten erwartet werden. Dieser gezielte Ansatz reduziert die Verarbeitungszeit und beschleunigt die Datenextraktion.
3. Niedrigere Kosten für stabile Formate
Wenn sich das Dokumentlayout nicht häufig ändert, müssen zonale Vorlagen im Laufe der Zeit kaum bis gar nicht angepasst werden. Dies reduziert die Einrichtungs- und Wartungskosten und macht es zu einer kostengünstigen Lösung für stabile, vorhersehbare Dokumenttypen.
Einschränkungen der zonalen OCR
Zonal OCR glänzt, wenn es um standardisierte, statische Formen geht. In realen Szenarien bleiben Dokumente jedoch selten konsistent. Anbieter optimieren Layouts, neue Vorlagen entstehen und gescannte Bilder unterscheiden sich oft in der Qualität. Aufgrund dieser Herausforderungen ist zonales OCR fragil und kostspielig in der Wartung. Hier ist der Grund:

Starre Vorlagenabhängigkeit
Jedes Mal, wenn sich das Layout eines Dokuments auch nur geringfügig ändert, müssen Sie Vorlagen aktualisieren oder neu erstellen. Im großen Maßstab wird dies zu einer nie endenden Aufgabe.
Schlechte Anpassungsfähigkeit
Zonal OCR kann keine unstrukturierten oder halbstrukturierten Dokumente wie Rechnungen, Verträge oder Hypothekendateien verarbeiten, bei denen die Feldpositionen variieren.
Eingeschränktes Datenverständnis
Das System extrahiert nur Text — es versteht nicht, was dieser Text bedeutet. Es kann beispielsweise nicht erkennen, ob „12/08/24“ ein Datum oder ein Teil einer Adresse ist.
Die Validierung erfordert zusätzlichen Aufwand
Einfache Regelprüfungen sind möglich, aber erweiterte dokumentübergreifende Validierungen (z. B. der Abgleich von Beträgen zwischen Formularen) sind nicht möglich.
Probleme mit der Skalierbarkeit
Die Verwaltung von Hunderten von Vorlagen in mehreren Abteilungen wird schnell zu einem Wartungsalbtraum.
Umgang mit sich wiederholenden und zusammengesetzten Feldern
Eine der größten Schwächen der zonalen OCR ist ihre Unfähigkeit, sich wiederholende Daten oder zusammengesetzte Felder zuverlässig zu erfassen. Vorlagen eignen sich gut für Einzelwerte wie „Rechnungsnummer“ oder „Gesamtbetrag“, gehen aber kaputt, wenn es um Dokumente geht, die Folgendes enthalten:
- Einzelposten oder Tabellen: Rechnungen, Bestellungen und Versandformulare enthalten häufig Zeilen mit Produktdetails. Eine feste Zone kann nur eine Dateninstanz erfassen, nicht eine gesamte dynamische Tabelle.
- Zusammengesetzte Felder: Einige Zonen können mehrere Werte in einem Block enthalten (z. B. „Adresse“, die Straße, Stadt, Bundesland und Postleitzahl enthält). Zonal OCR kann diese Komponenten nicht intelligent trennen oder beschriften.
- Abschnitte mit variabler Länge: Wiederholte Felder, die je nach Transaktion wachsen oder schrumpfen, wie z. B. mehrseitige Kontoauszüge, können nicht mit starren Vorlagen verarbeitet werden.
Unterschiede zwischen zonaler OCR, Ganzseiten-OCR und KI-Datenextraktion
Wenn es um die Extraktion von Dokumentendaten geht, sind nicht alle Ansätze gleich. Gehen Sie wie folgt vor Zonales OCR, Ganzseitige OCR, und KI-basierte Extraktion (IDP) gegeneinander aufstapeln:
Warum Unternehmen von zonaler OCR zu IDP übergehen
Zonale OCR erfüllte ihren Zweck, als die Dokumentlayouts vorhersehbar waren und sich nur selten änderten. Dabei werden Daten aus festen Bereichen auf einer Seite extrahiert, was bei standardisierten Formularen wie Schecks oder Stromrechnungen sinnvoll ist. Aber hier ist das Problem: Die heutigen Geschäftsdokumente sind nicht statisch. Die Layouts variieren je nach Anbieter, Region und sogar im Laufe der Zeit. Die Pflege von Vorlagen wird kostspielig und fehleranfällig.
Das ist wo Intelligente Dokumentenverarbeitung (IDP) tritt ein. Im Gegensatz zu Zonal OCR stützt sich IDP nicht auf starre Vorlagen. Es verwendet KI, maschinelles Lernen und natürliche Sprachverarbeitung Dokumente so zu verstehen, wie es Menschen tun. Es kann Dateien klassifizieren, wichtige Daten aus halbstrukturierten oder unstrukturierten Formaten extrahieren und diese Informationen sogar anhand von Geschäftsregeln oder externen Systemen validieren — alles automatisch.
Kurz gesagt:
- Zonales OCR liest Text aus einer festen Box.
- IDP versteht den Kontext, passt sich neuen Layouts an und skaliert mühelos.
Für Unternehmen, die mit Rechnungen zu tun haben, Hypothekendateien, technische Zeichnungen, oder Versicherungsdokumente, IDP ist nicht nur ein Upgrade, es ist eine Notwendigkeit für Geschwindigkeit, Genauigkeit und Konformität.
Ausblick auf die Zukunft
Zonales OCR wird weiterhin einen festen Platz in Workflows haben, die auf festen, stark strukturierten Dokumenten basieren. Geschäftsprozesse entwickeln sich jedoch weiter, und die Variabilität von Dokumenten wird zur Norm. Statische Vorlagen können mit diesem Maß an Veränderungen nicht Schritt halten. Die Zukunft gehört Systemen, die Intelligenz mit Automatisierungslösungen kombinieren, die Daten nicht nur lesen, sondern sie auch im Kontext verstehen. Das ist der Ort, an dem IDP wird unverzichtbar.
Für Unternehmen, die ihren Betrieb zukunftssicher machen möchten, ist das zu IDP wechseln ist nicht mehr optional; es ist der nächste Schritt vorwärts.

Bhavika Bhatia ist Produkttexterin bei Infrrd. Sie verbindet Neugier mit Klarheit, um Inhalte zu erstellen, die komplexe Technologien einfach und menschlich anfühlen lassen. Mit einem philosophischen Hintergrund und einem Händchen für Geschichtenerzählen verwandelt sie große Ideen in aussagekräftige Erzählungen. Außerhalb der Arbeit jagt sie oft nach der perfekten Café-Ecke, schaut sich eine neue Serie an oder verliert sich in einem Buch, das mehr Fragen als Antworten aufwirft
Häufig gestellte Fragen
Software zur Überprüfung und Prüfung von Hypotheken ist ein Sammelbegriff für Tools zur Automatisierung und Rationalisierung des Prozesses der Kreditbewertung. Es hilft Finanzinstituten dabei, die Qualität, die Einhaltung der Vorschriften und das Risiko von Krediten zu beurteilen, indem sie Kreditdaten, Dokumente und Kreditnehmerinformationen analysiert. Diese Software stellt sicher, dass Kredite den regulatorischen Standards entsprechen, reduziert das Fehlerrisiko und beschleunigt den Überprüfungsprozess, wodurch er effizienter und genauer wird.
IDP verarbeitet effizient sowohl strukturierte als auch unstrukturierte Daten, sodass Unternehmen relevante Informationen aus verschiedenen Dokumenttypen nahtlos extrahieren können.
KI verwendet Mustererkennung und Natural Language Processing (NLP), um Dokumente genauer zu klassifizieren, selbst bei unstrukturierten oder halbstrukturierten Daten.
IDP nutzt KI-gestützte Validierungstechniken, um sicherzustellen, dass die extrahierten Daten korrekt sind, wodurch menschliche Fehler reduziert und die allgemeine Datenqualität verbessert wird.
IDP (Intelligent Document Processing) verbessert die Audit-QC, indem es automatisch Daten aus Kreditakten und Dokumenten extrahiert und analysiert und so Genauigkeit, Konformität und Qualität gewährleistet. Es optimiert den Überprüfungsprozess, reduziert Fehler und stellt sicher, dass die gesamte Dokumentation den behördlichen Standards und Unternehmensrichtlinien entspricht, wodurch Audits effizienter und zuverlässiger werden.
Wählen Sie eine Software, die fortschrittliche Automatisierungstechnologie für effiziente Audits, leistungsstarke Compliance-Funktionen, anpassbare Audit-Trails und Berichte in Echtzeit bietet. Stellen Sie sicher, dass sie sich gut in Ihre vorhandenen Systeme integrieren lässt und Skalierbarkeit, zuverlässigen Kundensupport und positive Nutzerbewertungen bietet.





