
Say you open a folder filled with 1,000 scanned invoices. Each document has vendor logos, disclaimers, and long blocks of text. But all you need are three details like Invoice Number, Invoice Date, and Total Amount.
If you rely on traditional OCR, the system will read every word on every page. Then, you’ll have to sift through all that raw text to find the information you need. That means more processing time, more manual effort, and more chances for errors.
Zonal OCR offers a smarter way. Instead of scanning an entire page, it focuses on predefined areas called zones and extracts only the fields that matter. This targeted approach makes Zonal OCR faster and more accurate for documents with predictable layouts.
Let’s take a deep dive into what Zonal OCR is, how it works, where it excels, and where it falls short. We’ll also take a closer look at why businesses are shifting to Intelligent Document Processing (IDP) and what that means for the future of automation.
What is a Zonal OCR?
Zonal OCR, also called template-based OCR, reads text only from predefined areas on a page. These areas are zones that you create using a sample document.
Imagine you have an invoice with the total amount printed at the bottom right corner every time. With Zonal OCR, you can define a box over that area and label it “Total.” From then on, the system reads only that section when processing similar invoices.
How It Differs from Full-Page OCR
- Full-page OCR scans the entire document. It outputs all text as plain text or a searchable PDF. That means more cleanup work later.
- Zonal OCR extracts only specific fields. The data comes in structured formats like JSON, XML, or CSV, making it ready for automation workflows.
This approach saves time and reduces errors, provided that layouts are consistent.
Why Zonal OCR Still Matters
Why do companies still use Zonal OCR when there are advanced options like IDP? The answer is simple: predictable layouts.
If your documents rarely change format, Zonal OCR can deliver speed and accuracy at a lower cost. Examples include:
- Utility bills
- Bank checks
- Standardized tax forms
- Shipping labels
Here’s why Zonal OCR works well in these cases:
- Accuracy: Reads only marked zones, avoiding noise from other text.
- Speed: Processes small sections, reducing the time needed per document.
- Structured output: No need to parse long text files. Fields come labeled and ready.
- Lower infrastructure requirements: Simpler setup compared to advanced AI systems.
How Zonal OCR Works
Zonal OCR might sound technical, but its workflow is fairly simple. It revolves around extracting text from predefined areas (or “zones”) on a document. Here’s how the process unfolds:
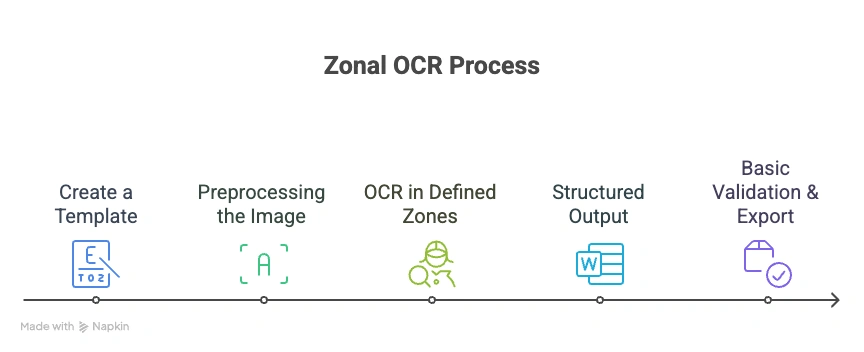
Step 1: Create a Template
Start by uploading a sample document that represents the standard layout. Then, manually draw rectangles around the fields you want to capture, such as Invoice Number, Customer Name, or Amount Due. Assign labels to each zone so the system knows what data to extract.
This template becomes the foundation for processing all similar documents.
Step 2: Preprocessing the Image
Before OCR kicks in, the system optimizes the scanned document to improve text recognition. Common preprocessing tasks include:
- Deskewing: Straightens tilted scans to align text properly.
- Noise Reduction: Removes marks, smudges, and shadows that could confuse OCR.
- Thresholding: Enhances the contrast between text and background for better readability.
These steps are crucial for accuracy, especially when dealing with low-quality scans.
Step 3: OCR in Defined Zones
Once preprocessing is complete, the OCR engine focuses only on the predefined zones. Everything outside those boxes is ignored, reducing processing time and errors.
This selective approach works well for structured, repeatable forms.
Step 4: Structured Output
The extracted data is mapped to the corresponding field labels and exported in structured formats like CSV, JSON, or XML. This makes it easy to push the data into ERP systems, CRMs, or other downstream applications.
Step 5: Basic Validation & Export
To prevent common errors, you can apply simple validation rules such as:
- “Field must be numeric”
- “Value must match date format (MM/DD/YYYY)”
After validation, the cleaned data is sent to your business system for processing.
While this process works efficiently for uniform documents, it struggles when layouts vary even slightly, which is why many businesses are transitioning to Intelligent Document Processing (IDP) for flexibility and scalability.
The Science Behind Zonal OCR
Zonal OCR is rooted in classic OCR principles. Research highlights two major factors behind its performance:
- Segmentation
- The document is divided into smaller sections for analysis.
- Methods include top-down (splitting large blocks into smaller zones) and bottom-up (grouping small elements into larger structures like words and lines).
- The document is divided into smaller sections for analysis.
- Preprocessing
- Image quality impacts OCR accuracy. Deskewing, denoising, and contrast adjustments are essential for success.
These steps ensure that the text within zones is clean and easy for OCR engines to read.
Primary Use Cases of Zonal OCR
Zonal OCR is at its strongest when working with documents that have static, predictable layouts. These documents typically use fixed positions for key fields, making template-based extraction feasible and efficient. Here are some common scenarios where Zonal OCR delivers real value:
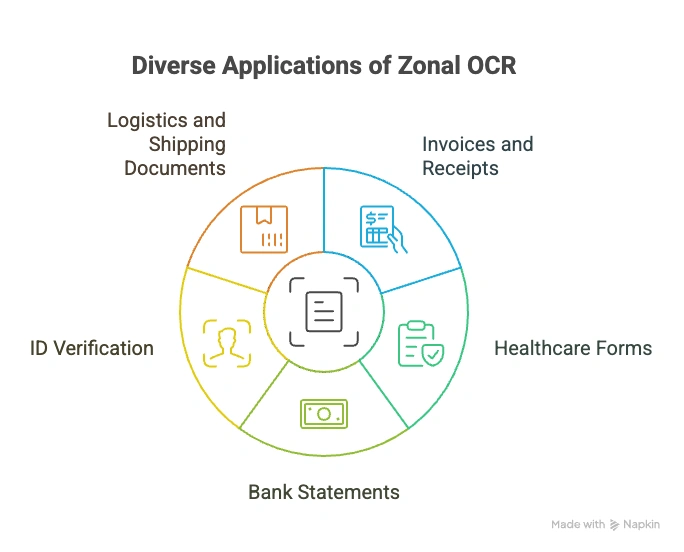
1. Invoices and Receipts
For vendors or partners that use a standardized invoice format, Zonal OCR can quickly capture essential details such as:
- Invoice Number
- Issue Date
- Total Amount
Instead of parsing disclaimers, terms, or footnotes, Zonal OCR focuses on the fields you define, speeding up processing for bulk invoice uploads.
2. Healthcare Forms
Medical environments still rely heavily on structured forms like admission sheets or insurance claims. Zonal OCR can accurately pull:
- Patient ID
- Diagnosis Codes (ICD codes)
- Admission and Discharge Dates
This selective approach reduces manual data entry and accelerates claims and reporting processes.
3. Bank Statements
When handling recurring bank statement formats, Zonal OCR excels at extracting:
- Current Balance
- Account Holder Information
- Summary of Transactions
By ignoring marketing messages or irrelevant notes, it delivers clean, structured data for reconciliation or compliance checks.
4. ID Verification
Identity documents such as driver’s licenses or passports are highly structured, making them perfect for Zonal OCR. Commonly extracted details include:
- Full Name
- Date of Birth
- Document Number
This is particularly useful for KYC (Know Your Customer) processes in banking and fintech.
5. Logistics and Shipping Documents
In logistics, standardized paperwork like bills of lading or packing slips makes template-based OCR practical. Zonal OCR can capture:
- Shipment ID
- Delivery Address
- Carrier Details
This ensures faster processing in warehouses or customs clearance.
Advantages of Zonal OCR
1. High accuracy on fixed layouts
Zonal OCR works best when documents follow the same structure or template. Because the system knows exactly where to look for information, the error rate stays very low compared to full-page OCR that must interpret everything.
2. Faster than full-page OCR
Instead of scanning and analyzing the entire page, Zonal OCR only focuses on specific zones where data is expected. This targeted approach reduces processing time and speeds up data extraction.
3. Lower costs for stable formats
When document layouts don’t change often, zonal templates require little to no adjustment over time. This reduces setup and maintenance costs, making it a cost-effective solution for stable, predictable document types.
Limitations of Zonal OCR
Zonal OCR shines when dealing with standardized, static forms. But in real-world scenarios, documents rarely stay consistent. Vendors tweak layouts, new templates emerge, and scanned images often vary in quality. These challenges make Zonal OCR fragile and costly to maintain. Here’s why:

Rigid Template Dependency
Every time a document layout changes even slightly, you must update or recreate templates. At scale, this becomes a never-ending task.
Poor Adaptability
Zonal OCR can’t handle unstructured or semi-structured documents like invoices, contracts, or mortgage files where field positions vary.
Limited Data Understanding
The system only extracts text—it doesn’t understand what that text means. For example, it can’t tell if “12/08/24” is a date or part of an address.
Validation Requires Extra Effort
Basic rule checks are possible, but advanced cross-document validations (e.g., matching amounts across forms) are out of reach.
Scalability Issues
Managing hundreds of templates across multiple departments quickly becomes a maintenance nightmare.
Handling Repeating and Compound Fields
One of the biggest weaknesses of Zonal OCR is its inability to reliably capture repeating data or compound fields. Templates work well for single values like “Invoice Number” or “Total Amount,” but break down when faced with documents that contain:
- Line items or tables: Invoices, purchase orders, and shipping forms often include rows of product details. A fixed zone can only capture one instance of data, not an entire dynamic table.
- Compound fields: Some zones may include multiple values in one block (e.g., “Address” containing street, city, state, and postal code). Zonal OCR cannot intelligently separate or label those components.
- Variable-length sections: Repeating fields that grow or shrink depending on the transaction, such as multi-page statements, can’t be handled by rigid templates.
Differences Between Zonal OCR, Full page OCR, and AI -data extraction
When it comes to document data extraction, not all approaches are created equal. Here’s how Zonal OCR, Full-Page OCR, and AI-Based Extraction (IDP) stack up against each other:
Why Businesses are Moving Beyond Zonal OCR to IDP
Zonal OCR served its purpose when document layouts were predictable and rarely changed. It works by extracting data from fixed zones on a page, which makes sense for standardized forms like cheques or utility bills. But here’s the problem: today’s business documents aren’t static. Layouts vary by vendor, region, and even over time. Maintaining templates becomes costly and error-prone.
This is where Intelligent Document Processing (IDP) steps in a turning point in any ocr vs idp comparison. Unlike Zonal OCR, IDP doesn’t rely on rigid templates. It uses AI, machine learning, and natural language processing to understand documents the way humans do. It can classify files, extract key data from semi-structured or unstructured formats, and even validate that information against business rules or external systems, all automatically.
In short:
- Zonal OCR reads text from a fixed box.
- IDP understands context, adapts to new layouts, and scales effortlessly.

For businesses dealing with invoices, mortgage files, engineering drawings, or insurance documents, IDP isn’t just an upgrade; it’s a necessity for speed, accuracy, and compliance.
Future Outlook
Zonal OCR will continue to have a place in workflows that rely on fixed, highly structured documents. However, business processes are evolving, and document variability is becoming the norm. Static templates can’t keep up with that level of change. The future belongs to systems that combine intelligence with automation solutions that not only read data but understand it in context. That’s where IDP becomes indispensable.
For organizations looking to future-proof their operations, the shift to IDP isn’t optional anymore; it’s the next step forward.

Bhavika Bhatia is a Product Copywriter at Infrrd who blends curiosity with clarity to craft content that makes complex tech feel simple and human. With a background in philosophy and a knack for storytelling, she turns big ideas into meaningful narratives. Outside of work, you’ll find her chasing the perfect café corner, binge-watching a new series, or lost in a book that sparks more questions than answers





