
A decade of running startups has taught me one thing about myself - I am wrong a lot of times. I have been so sure about having hired rock star team members who proved me wrong when they did not deliver. More than a few times, I was sure about some investors putting money in my ventures that ultimately did not sign the dotted line. I have personally lost a lot of money on companies that I thought would change the world. Life has taught me that I am wrong more often than I am right.
Around this time last year, I wrote a post about how 2022 was going to be the year of No Touch Processing (NTP) for Infrrd. Fast forward 12 months, and I am delighted to report that on this one occasion, I was not wrong. Yes, 2022 was an amazing year for No Touch Processing. Infrrd delivered on this promise and led a lot of our customers to the land of AI certainty. This was largely thanks to our stupendous Research Team that kept delivering marvels. It was a rocky ride, but we did it!
Straight Through Processing (STP) vs. No-Touch Processing (NTP)
While we had impossible technology and services to deliver in order to achieve no-touch processing, our biggest challenge turned out to be something else. There are a lot of solutions in the market that claim to deliver 90% straight-through processing (STP). So, a lot of customers believed that they already had what we were pitching to them. But there is a huge difference between NTP and STP… massive!
It was a big challenge explaining that to customers, especially in areas like order processing, supply chain management, procurement, logistics, and planning. Many businesses assumed their decision-making software, payment systems, and accounts processing were already optimized. However, true No-Touch Processing (NTP) goes beyond setting up automated orders and invoices—it transforms the entire supply and order chain into a seamless, intelligent workflow.
Allow me to elaborate.

Most solutions work on the concept of a “confidence score” for the data they read. They use this score to tell you that they are 90% sure that they have extracted the data correctly from your invoices, account papers or any other form of document. You test it and see that most of the time when the confidence score is 90%, the system is correct. So you configure a rule that says when the confidence is 90%, go with what the system management says. This is called Straight Through Processing. But when it comes to dealing with procurement and payment, there are two huge problems with STP:
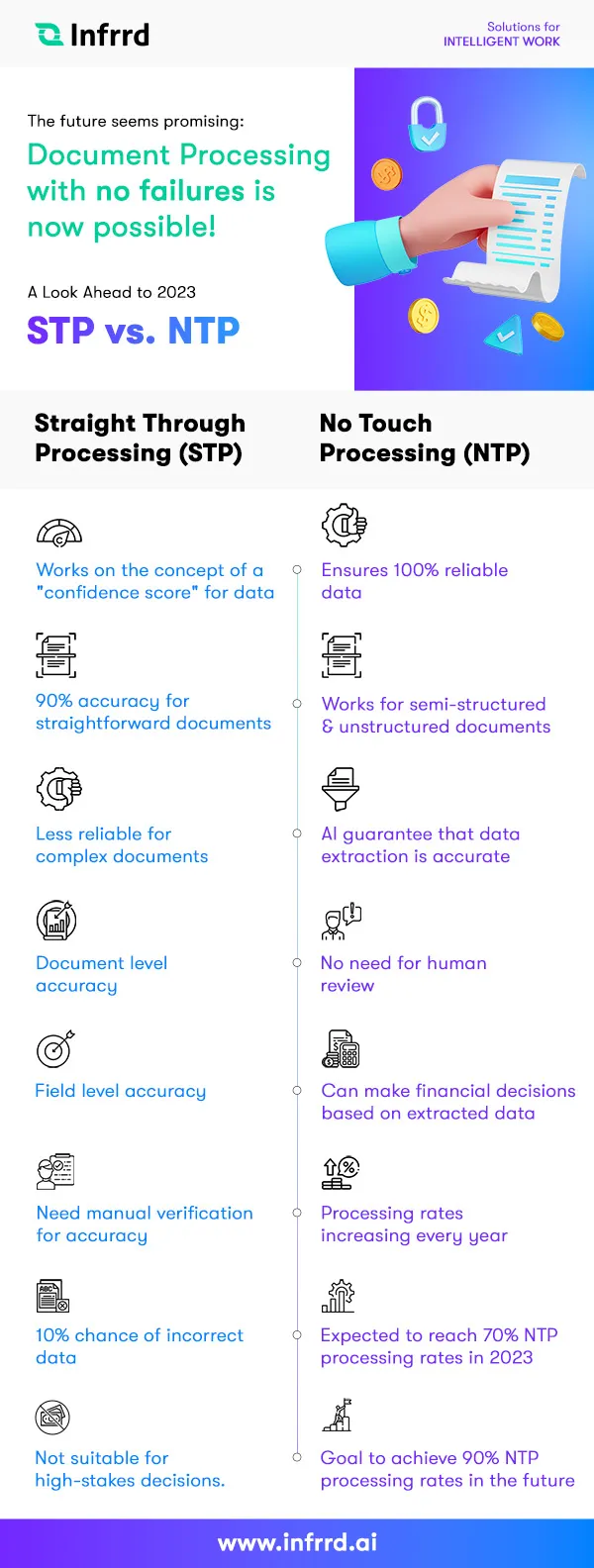
Problem #1 - Where is my 10%?
You will need to refresh your 8th-grade Algebra books to understand the first problem. When a system tells you that it is 90% sure about the extracted data, it is also saying that there is a 10% chance that it is 100% wrong. Otherwise said, one in 10 documents that have a 90% confidence score could be completely wrong. Imagine if you took an important financial decision based on this data. For example, you paid out an invoice of $90,000 instead of $9,000! Or approved a mortgage loan for $3 million instead of $300,000.
So, customers usually do not make such logistics decisions based on STP documents. They still need teams to verify these documents manually. And that is a costly investment.
Problem #2 - STP and Semi/Unstructured Data
Second, STP rates of 90% only work for straightforward documents that fit into a template. As documents grow in variations from hundreds to millions, the 90% confidence rates do not hold. Now, I am not saying that no one provides 90% confidence for semi-structured data, but as documents become more complex, this 90% confidence becomes less reliable. So most customers use it for fixed format documents such as forms, etc.
Problem #3 - Document Level Accuracy vs. Field Level Accuracy
To understand this problem, you will need a piece of paper, a pen, and a scientific calculator. Ready? Here goes - if a document has 10 data points for extraction and each of them is extracted with 90% confidence, then what is the confidence level for the entire document?
If your answer is 90%, then you are wrong. Indulge me for a moment. The probability of two events happening at the same time is the product of their individual productivity. So, if event one has a 90% probability, it must occur with a second event that also has a 90% probability, which then combined probability for both of them happening together is:
0.9 X 0.9 = 0.81 or 81%
So, when you apply the same math to 10 fields in a document extracted with 90% accuracy each, then the result is:
0.9 X 0.9 X 0.9 X 0.9 X 0.9 X 0.9 X 0.9 X 0.9 X 0.9 X 0.9 = 0.3486 or 34.86%
Will you make financial decisions on a document with a 34% probability of being correct?
It’s not likely.
No-Touch Processing, is it actually Touchless?
NTP addresses all these problems. NTP ensures that you get 100%, not 90%, not 99% reliable data that does not need human reviews. It works for semi-structured documents as well as unstructured documents. Basically, it is AI’s guarantee that it has done a really good job with the extracted data and that you do not need to look at it. We have put 7 years of fundamental research toward this concept, as well as have filed and granted several patents into making this happen.
Achieving no-touch processing wasn’t just about technology and services—our biggest challenge was explaining the massive difference between NTP and STP. Many believed their existing order processing, supply chain, procurement, logistics, and planning systems already delivered what we offered.
True NTP transforms decision-making software, payment systems, accounts, and invoices into a seamless, intelligent workflow. We started the year with 18% NTP order processing, meaning 18 out of 100 documents required no human review. Some customers now exceed 57%, and with continued AI research in reasoning and certainty, we aim to surpass 70%—on our way to the beloved 90%
Not too far out in the future, when you apply for a mortgage online and upload your documents for better management, you will get a loan decision instantly because the AI and no-touch processing has perfectly read your documents and there was no need to wait for a human review. Infrrd is on a mission to make that happen!
Happy Holidays and a Very Happy New Year, Everyone!






