
2021 is slowly coming to an end. This was a big year for Intelligent Document Processing platforms. They gained a lot of traction and made inroads into a lot of operations teams, improving their efficiency and saving costs along the way. Analyst recognition of this segment broadened in 2021 with Gartner, ISG, Quadrant, and many other analysts joining Everest and Zinnov to cover the intelligent document processing/ automated document processing space, leading to broader Zinnov recognition in IDP. A lot more customers have now started to notice the possibility that this technology presents to process even the most unstructures documents and actively started pilots for wider adoption across enterprises.
Over the last few years, customers were cautiously adopting Intelligent Document Processing, sceptical of the efficiency gains that can be achieved by this technology. Now that a lot of them have seen what is possible with intelligent document process automation, they are asking questions about what else can be done and also pushing the boundaries of what is possible. This year, Straight Through Processing of Intelligent Document Processing showed up in a lot of our customer conversations. Customers started asking about what it would take for the Intelligent Document Processing solutions to handle and process documents completely independently of human intervention. But we told them, we have something even better than Straight Through Processing - Infrrd's own no-touch automated document processing.

What is the big deal with no-touch automated document processing?

Unlike humans, algorithms don’t need sleep, coffee breaks, or time off. They’re capable of running 24/7, processing vast amounts of data with speed and consistency. But there’s one critical bottleneck: human intervention in straight through processing. Even the most advanced systems pause when they encounter unclear data or ambiguous formats, waiting for someone to step in and make a judgment call. This manual oversight not only slows things down but also limits the true potential of document process automation.
That’s where No-touch Intelligent Document Processing (IDP) and Intelligent Process Automation (IPA) come in. The more AI can rely on itself rather than an external input, the more scalable it becomes. We have posted in detail about the case for low-touch mortgage processing in one of our past posts. By combining AI, machine learning, and natural language processing, No Touch Intelligent Document Processing enables systems to accurately read, interpret, and understand even complex documents—without stopping for human review. And when integrated into broader Intelligent Process Automation workflows, this hands-off approach transforms how businesses operate.
No-touch automated document processing simplified
No Touch Intelligent Document Processing (IDP) is exactly what it sounds like — and it’s a key capability to look for in no-touch IDP software when comparing vendors. A document process automation method so accurate and efficient that even large volumes of unstructured documents can be processed without any human involvement, unless absolutely necessary.
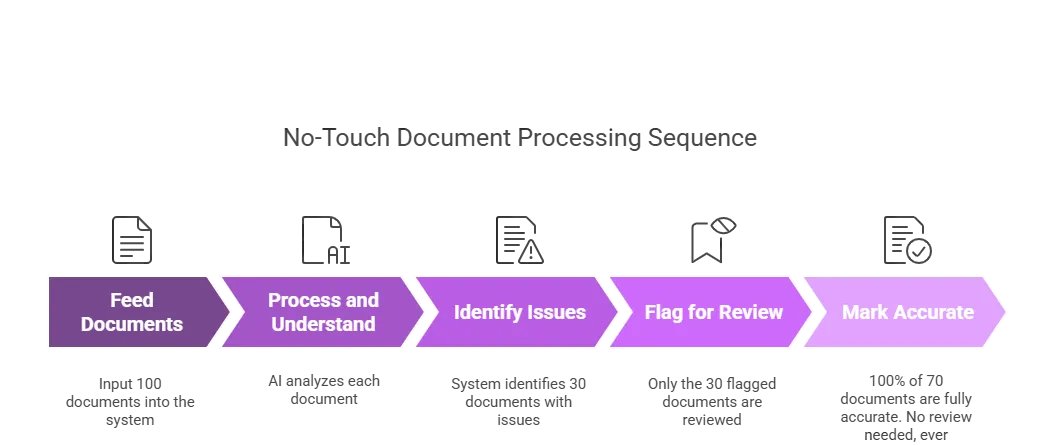
Let’s break it down with a simple example. Imagine you have 100 documents that need to be processed. With traditional Straight Through document process automation systems, you feed all 100 documents into the system, and it tells you that 70 were processed successfully while 30 might have issues. The problem here is that system doesn’t tell you which 30 documents failed. So, your team still has to manually go through all 100 documents to identify and verify the problematic ones, completely defeating the purpose of automation. That’s not intelligent. That’s just shifting the burden around.
Now, this is where Infrrd’s No Touch automated document processing sets itself apart. Using advanced AI and validation logic, the system doesn’t just process documents—it understands them. So in that same scenario, when 100 documents are submitted, Infrrd’s platform not only processes them but also pinpoints exactly which 30 documents have issues. It then flags those 30 for review, while confidently marking the remaining 70 as fully accurate and ready to move forward. No manual intervention needed. Those 70 documents don’t need to be touched again. That’s the magic of No Touch Automated Document Processing: it gives you complete confidence in your automation, minimizes human effort, and drastically accelerates your unstructured document processing workflows.
Field level accuracy with no-touch automated document processing
It’s time for a short riddle. You will need your probability and math skills to solve this one. Ready? Here goes - let’s say there is a document that you need to extract 5 fields from. Your highly accurate algorithms can extract each of these 5 fields with 90% accuracy. If any of these fields is wrong, then someone has to manually look into the document to see what the real value should be. Let’s call this number document-level accuracy. The question is, if each of your 5 fields is extracted with 90% accuracy, what is the document-level accuracy that you can achieve?
If you said 90%, you are wrong and not alone.
Most people make that mistake. It is easy to assume that if you get 90% accuracy on all fields, your overall accuracy should be 90%. But it does not work like that. When you get 90% accuracy, your algorithms are wrong 10% of the time. If you had 5 fields extracted, each of the 5 fields would be wrong 10% of the time, each. Even if 4 of these 5 fields are correct and only one is wrong, your document level accuracy is zero.
So, if you have 5 fields extracted with 10% error, your maximum error compounds to 5 times 10% = 50%. If you have 10 fields extracted at 90% accuracy, your overall document-level accuracy could be 0%.
For Intelligent Document Processing systems to produce Straight Through Processing, they have to be correct for all the fields, all the time. This is mathematically and technically very hard to achieve. That is why this problem has not been solved yet to this extent. But No touch intelligent document processing can solve these problem to a great extent and the future does look very promising.
The future looks very promising with no touch intelligent document processing
There are three key factors that look very promising for dramatic progress in no-touch document processing in the new year. These chess pieces are all lined up for the end game to begin:
1. Proven Capability
In the previous years, Intelligent Document Processing platforms have shown what they are capable of and have surprised many customers and industry pundits alike. Especially for customers who had tried Optical Character Recognition (OCR solutions) and other traditional Intelligent Processing Solutions with just Straight Through Document Processing. in the past and not seen the results that they were hoping to see, the last couple of years have delivered a lot of promise in efficiency and cost-cutting, all because of the revolutionary no-touch automated document processing. The question about this technology holding water has finally been answered. This has emboldened both the customers and the Intelligent Document Processing players to aspire to bigger goals.
2. Advancement in Machine Learning
This was a landmark year for automation, especially in the world of intelligent document processing.
This was the year Intelligent Document Processing (IDP) truly came of age. Breakthroughs in machine learning redefined what algorithms could do. They didn’t just scan and sort anymore they began to see, read, understand, and process documents with near-human intelligence and with advanced level of autonomy. And at the heart of it all is No-Touch Automated Document Processing.
We’re not just talking about traditional document process automation where systems process data in bulk and flag errors vaguely. That era is behind us. Today’s Intelligent Document Processing platforms go further. They know exactly which documents are correct and which need human attention. They can make decisions, validate information, and automate document workflows end-to-end with zero human intervention.
No-Touch Automated Document Processing doesn’t just make things faster. It eliminates friction. It frees up human teams. It transforms compliance-heavy, unstructured document-heavy operations. As Intelligent Document Processing platforms continue to evolve, No-Touch automated document Processing will no longer be a premium feature. It will be the new standard.
3. Incentives
Innovative customers have started incentivizing Intelligent Document Processing deals based on outcomes, rewarding higher risk of automation with higher reward. This works both ways - the customers save on their operational costs in and pass on a share of that to the Intelligent Document Processing vendors. As a result, product engineering teams are pushing harder than ever to race to be the first ones to capture no-touch document processing automation.
All in all, the future seems to be a really promising year for no-touch intelligent document processing. Our research and engineering teams are very excited about what they will put in front of our customers in the new year. We hope to set even higher standards for no-touch automated document processing and accuracy.






