
Gartner recently released, “Infographic: Understand Intelligent Document Processing”. According to Gartner, “The market for document capture, extraction and processing is highly fragmented. Data and analytics leaders should use this research to understand the process flow and differentiated capabilities offered by intelligent document processing solutions.” In this series of posts, we will speak to the 6 critical flows in IDP that Gartner covers and how Infrrd solutions stack up.
1. Capture or Ingestion
2. Document Pre-processing
3. Document Classification
4. Data Extraction
5. IDP data validation feedback loop
6. Integration
In this first post, we explore the whole Intelligent Document Processing workflow, from pre-processing to post processing — a foundation for evaluating intelligent document processing tools effectively.
Why Intelligent Document Processing?
If you are in the business of document processing where a large volume of documents are processed - be it invoices, receipts, insurance forms, or healthcare documents - you may be considering migrating or have already migrated to an automated process to remain competitive. This is where Intelligent Document Processing, or IDP, solutions can be a powerful way to transform your business.
Intelligent Document Processing (IDP) is the buzzword when it comes to document processing automation. With Intelligent Document Processing (IDP) solutions, documents are processed at an exponential pace and high level of accuracy aiming at touchless strategy, which means minimal manual efforts.
Intelligent Document Processing (IDP) focuses primarily on gaining meaningful inferences and relevant information from variations in documents from different document types, such as unstructured, semi-structured, and structured.
Pre-processing in IDP solutions can be broadly categorized into two areas
1. Automated capture or ingestion
2. Automated pre-processing
Step 1 of Intelligent Document Pre-Processing: Document Capture or Ingestion
The first phase of document processing by an Intelligent Document processing (IDP) solution is smart capture or ingestion. Optical Character Recognition (OCR) and powerful machine learning algorithms play a major role here.
In simple terms, your business is an accumulation of data, starting from a client email to complex inventory or invoice documents. You can broadly classify this data into three categories:
- Structured: This is the most organized data where information is well structured. For example, a government form or tabular data in an Excel sheet.
- Unstructured: This is unorganized data and is the most complex to process. Information may be in different formats, such as an image, a video, an audio file, an email message, or even news articles.
- Semi-structured: This is a blend of structured and unstructured data. For example, invoices, purchase orders, bills of lading, contract documents, company annual reports, and so on.
As per the data, in the real world more than 75% of data is either in an unstructured or semi-structured format. To automatically process and structure this data competitively for a large volume of documents, you need a robust and efficient IDP solution, such as Infrrd’s Intelligent Document Processing (IDP), so that you do not compromise on time, accuracy, and efficiency as compared to your competitors.
So, how does an AI-based Intelligent Document Processing (IDP) solution handle data, especially unstructured and semi-structured?
IDP systems use AI-based optical character recognition (OCR) which is used with technologies, such as computer vision and natural language processing(NLP). Optical Character Recognition (OCR) is primarily used to detect language-related characters, letters, numbers, etc. Traditional OCR has a high dependency on structured data. However, with computer vision and NLP, the capabilities of OCR to handle unstructured and semi-structured data have undergone a paradigm shift.
IDP solutions recognize the data extracted by OCR and enable you to structure it based on the data types, irrespective of whether the documents are structured, unstructured, or semi-structured. Moreover, machine learning algorithms in IDP systems enable the system to exponentially learn from training and corrections each time a document is processed.
Step 2 of Intelligent Document Pre-Processing: Document Pre-Processing
In Intelligent Document Processing (IDP) solutions, documents pass through the pre-processing stage where OCR and machine learning algorithms evaluate the document quality and implement resolution measures before actual extraction. Document pre-processing is an important step to ensure high-quality extraction. It refers to cleaning, organizing, and transforming the raw data to match the quality expected or mandated by the Intelligent Document Processing (IDP) or machine learning models. It is primarily a data mining technique aimed at improving document quality.
Infrrd’s Intellignet Document Processing (IDP) solution uses advanced AI technologies for document pre-processing. Let’s dive into the pre-processing strategies of IDP solutions.
Step 3 of Intellignet Document Pre-Processing: Data Annotation and Labeling
Document annotation and labeling is a configuration process where you are setting up your system to make it pre-processing-ready for bank statement processing.
IDP systems have a machine learning-first approach. This means that the documents are processed based on a configured machine learning model. Infrrd uses training, also known as tagging, to configure models for document processing. The configuration user or manager is equipped with data and annotation capabilities to train a specific document type, including the document fields. The data annotation or tagging is minimal when you use a pre-trained global model which has the potential to process documents with high accuracy for known document types. However, the data annotation features of Infrrd’s IDP enable you to easily configure, tag, and train even unknown document types.
Step 4 of Intelligent Document Pre-Processing: Merge or Split Documents
When you are processing hundreds or thousands of paper or digital documents, it is the practical reality to have numerous unstructured, unorganized multipage documents for processing. This is where the key pre-processing activities are automatically performed by IDP platforms, one of the keys is the merging or splitting of your documents.
Infrrd’s Intelligent Document Processing (IDP) solution uses technologies such as computer vision and NLP to analyze your documents and recognize their structure and layout to detect the documents that need to be split. You can upload a parent file and Infrrd’s system will recognize them, and then split them into individual documents to enable the inbuilt OCR engine for downstream processing, as shown.
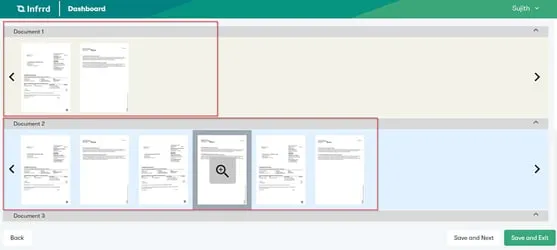
Step 5 of Intelligent Document Pre-Processing: Skew Correction
Intelligent Document Processing (IDP) systems offer the best extraction results when document elements, such as images and text, are in an upright position. However, in the real world, this scenario is far from true as you have multiple variations of documents, including unstructured physical copies, where many of the elements appear skewed. The text appears rotated or tilted in different angles. Think scanned documents. You need to correct the angular tilts and orientation before processing the document - literally to zero degrees. One of the popular techniques used by IDP solutions is skew correction, also known as deskewing. This process eliminates the manual efforts as skew correction is automated in Intelligent Document Processing (IDP).
Infrrd’s Intelligent Document Processing (IDP) solution uses a combination of coherent machine learning algorithms, deep learning models, OCR capabilities, and de-skew techniques and mechanisms, such as Hough Transform, to ensure exceptional skew correction results. The high-level flow of our deskew techniques include:
- Identifying the text blocks or images to be skewed
- Detecting the skewness and calculating the text angle
- Applying Infrrd de-skew mechanisms to correct the skew to zero angles

Step 6 of Intelligent Document Pre-Processing: Denoising
Denoising is the process of detecting and removing the grainy sections, such as black dots, blur, or shadows, and cleaning them up to restore better quality. The physical documents you upload may have deteriorated over time because of any number of reasons, such as dirt, stains, or wrinkles. This is where denoising becomes an important pre-processing activity for IDP systems.
Some of the Intelligent Document Processing (IDP) methods to denoise documents include:
- Median filtering: Primarily to peel out the white spaces in the background
- Edge detection, dilation, and erosion, also known as the EDE method: Detects unwanted elements, such as boxes or lines, and removes them
- Adaptive thresholding: Identifies unwanted elements by detecting the threshold value of pixels
- Linear regression: Performs a brightness and contrast correction by predicting the pixel intensity and linear relationship between sections that are clean and dirty
- Auto encoding: Segments data into layers to remove irrelevant elements
Infrrd’s Intelligent Document Processing (IDP) uses multiple techniques to denoise documents, some of which include adaptive thresholding, binarization, and Gaussian smoothing, also known as Gaussian blur or Gaussian function. Our unique and constantly evolving skew correction strategy focuses on transforming low-quality documents to comply with Infrrd’s extraction-readiness state.

Step 7 of Intellignet Document Pre-Processing: Data Validation and Correction
Data validation is a process to check the compatibility of the document, such as whether the document is in a valid format or if the resolution matches the defined specifications. Moreover, these are activities to define a certain level of quality for the raw data, such as identifying discrepancies between training set data and the data you need to process. The system automatically corrects most of the discrepancies identified at this stage. For example, if a document or an image you upload was captured in an old phone with low lighting, it will probably have low resolution, maybe 100 dots per inch (dpi). The Infrrd Intelligent Document Processing (IDP) system will automatically detect issues in such documents and increase the resolution before processing it, perhaps to 300 dpi.
Step 8 of Intelligent Document Pre-Processing: Taxonomies, Ontologies, Tags, and More
Another aspect to consider in an Intelligent Document Processing (IDP) solution are the options to integrate with taxonomies, ontologies, or tags. Taxonomies refer to the bottom-up approach of NER models to collect data in categories. Machine-language ontologies refer to identifying the pattern of various entities and relationships among the data. Tags refer to a key-value pair approach for data set tagging. The right set of tagging enables an AI system to be more effective and improve accuracy across document indexing workflows.
When all is said and done, make sure the Intelligent Document Processing (IDP) solution you invest in has exemplary capabilities for document pre-processing like Infrrd’s IDP. We recommend you make this a checkpoint when you evaluate or choose your Intelligent Document Processing technology partners.
In our next post, we explore Gartner’s description of Document Classification, and how Infrrd stacks up.
Source : Gartner, Infographic: Understand Intelligent Document Processing, Shubhangi Vashisth et al., 22 September 2021






