
Healthcare runs on data, but not all data is ready to run with.
In 2020, the industry produced 2.3 zettabytes of data. By 2025, that number will reach 10,000 exabytes. But from HL7 files and lab reports to handwritten notes and scanned forms, this information often sits locked in unusable formats.
This is where data extraction in the healthcare sector becomes essential.
It’s not just about pulling fields from forms. It’s about turning raw, chaotic inputs into usable, trusted information, fast enough for decisions that matter.
Scroll down to gain an in-depth understanding of why healthcare data is often scattered across formats and systems, how intelligent data extraction in healthcare turns that chaos into usable insights, and what that means for faster care, fewer errors, and better decisions. Because when healthcare runs on clean data, everything else runs better.
The Healthcare Data Explosion
Healthcare now accounts for nearly 30% of the world’s data volume.
Every interaction adds more:
- Appointment notes
- Lab results
- Wearable device data
- Claims and billing forms
- Diagnostic images
The problem isn’t volume, it’s variety. Structured HL7 files mix with handwritten intake forms making extracting structured information from documents essential in real-world workflows. Scanned prescriptions sit next to voice transcripts. Each department documents differently. Most systems weren’t designed to talk to each other.
The result? Trapped insights. Disconnected systems. Repeated manual work.
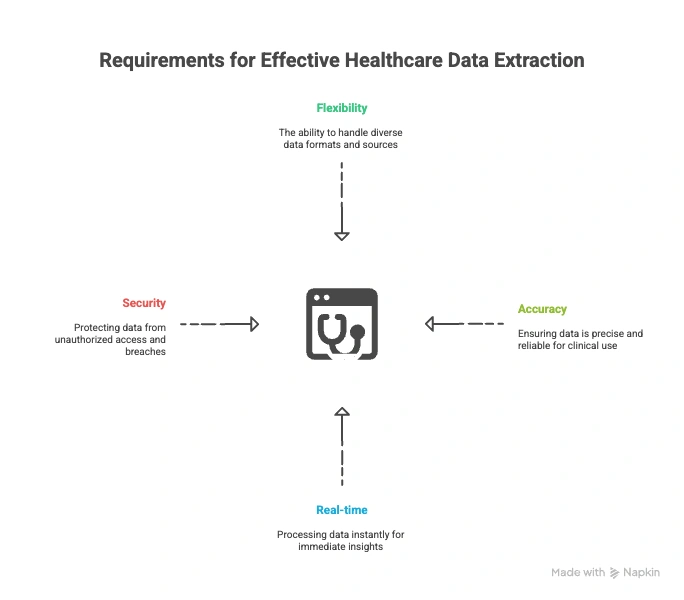
To fix that, healthcare data extraction must be:
- Flexible across formats and sources
- Accurate enough for clinical-grade use
- Real-time and secure
No more retyping. No more searching. Just structured, usable data when and where it’s needed.
Why Data Extraction in Healthcare is Essential for Smarter Care
When healthcare data is clean, complete, and ready to use, it powers everything from clinical decisions to claims processing. But when it’s not, the ripple effects are costly and dangerous.

Here’s what happens when extraction fails:
- Treatment delays from missing or mismatched patient data
- Billing errors that lead to denied claims and revenue loss
- Misdiagnoses caused by fragmented or outdated records
- Flawed research due to inconsistent datasets
A 2025 study in the Journal of Biomedical Informatics found that even small differences in ETL (Extract, Transform, Load) logic between hospitals led to major discrepancies in lab result interpretation—impacting both clinical outcomes and research reliability.
Data extraction isn’t just an IT function. It’s the first step in safe, high-quality care.
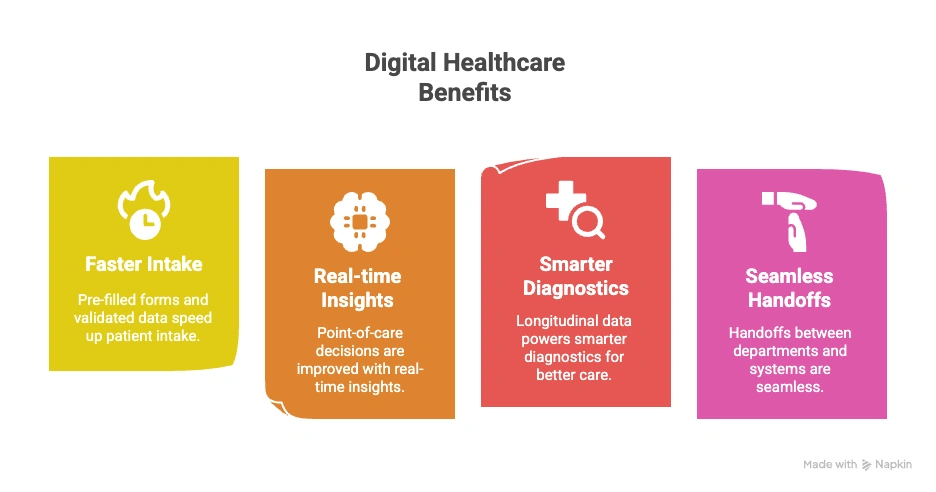
When done right, it enables:
-Faster patient intake with pre-filled forms and validated data
-Real-time insights for point-of-care decisions
-Smarter diagnostics powered by longitudinal data
-Seamless handoffs between departments and systems
It also lays the groundwork for value-based care, regulatory reporting, and health equity tracking.
The takeaway? Structured, reliable data isn't a luxury; it’s a necessity.
And data extraction is how you get there.
The Healthcare Analytics Market: Fueling the Data Revolution
The demand for structured, accurate healthcare data isn’t just a clinical priority; it’s a financial one. The global healthcare analytics market was worth $43.1 billion in 2023 and is projected to surpass $167 billion by 2030. Another forecast estimates $145.81 billion by 2032. The common thread? None of this is possible without clean data.
Whether it’s dashboards for hospital executives or AI models for predicting disease, every insight begins with data that’s been properly extracted, cleaned, and structured. Cluttered PDFs, handwritten forms, and disconnected systems won’t cut it.
As the healthcare industry shifts from volume-based to value-based care, clean data becomes the currency of performance. So now it boils down to the source. After all, where does the healthcare data come from?
Key Healthcare Documents for Data Extraction
To understand the importance of extraction, it's essential to know where healthcare data originates. Here are some of the most common and complex sources:
- EHRs: Patient histories, diagnoses, medications, allergies
- Lab Results: Numeric data, handwritten observations
- Claims & Billing Forms: Scanned, image-based forms (CMS-1500, UB-04)
- Patient Intake Forms: Often handwritten or faxed
- Prescriptions: Typed, handwritten, or full of physician shorthand
- Radiology & Imaging Reports: Rich but highly unstructured
- Discharge & Surgical Notes: Detailed but difficult to standardize
- Remote Monitors & Wearables: Real-time data streams
- Telehealth Transcripts: Semi-structured at best
Every source brings its own language, structure, and quirks. And smart data extraction systems must do more than extract; they must interpret.
For example, “CP” might mean chest pain in one context and cerebral palsy in another. The right system understands the difference.
Manual vs. Automated Data Extraction in Healthcare
Healthcare data can be processed in two ways: manually by people, or automatically by AI systems. Manual entry has been the norm for years, but it slows down workflows and leaves room for errors. Automated data extraction changes that by reading, classifying, and structuring information at scale.
In simple terms, manual extraction is slow and error-prone, while automation is fast, accurate, and built for modern healthcare data.
Methods of Data Extraction in the Healthcare Sector
There’s no one-size-fits-all method for data extraction. Each approach has strengths and limitations. The most common types include:
Template-Based Extraction: Great for static forms with predictable layouts. But if the structure shifts, it breaks. Fast, but inflexible.
Rule-Based Extraction: Follows rigid logic like “if X, extract Y.” Works with semi-structured data but struggles with variations in format, layout, or terminology.
AI-Powered Extraction: The most adaptive and scalable method. It uses machine learning and NLP to learn from patterns, understand context, and adapt to new document types. Whether it’s a scanned form, free-text note, or handwritten prescription, AI-based systems are built to evolve.
For real-world use, AI-based data extraction in the healthcare sector is becoming the gold standard.
How Data Extraction in the Healthcare Works: A Step-by-Step Guide
Understanding the process behind healthcare data extraction helps clarify where automation creates the most value. Here’s a streamlined breakdown:
1. Input Collection
The process begins by gathering input from various healthcare data sources. These may include scanned patient records, medical PDFs, faxes, diagnostic images, XML files, HL7/FHIR streams, or exports from Electronic Health Records (EHRs). A robust extraction system must handle multiple file types and formats, both structured and unstructured.
2. Preprocessing
Before extraction begins, the documents are preprocessed to improve machine readability. This step involves noise reduction (removing marks or smudges from scans), skew correction (aligning tilted documents), and image enhancement to improve clarity. Effective preprocessing is vital for ensuring that downstream extraction is accurate—especially in high-stakes healthcare workflows.
3. Document Classification
Next, the system automatically identifies the document type—whether it's a lab report, prescription, discharge summary, billing form, or patient intake sheet. Classification allows the system to apply tailored extraction logic depending on the structure and terminology of each document category.
4. Field-Level Data Extraction
This is the core of data extraction in the healthcare sector. Here, specific fields such as patient names, admission dates, ICD or CPT codes, lab values, and physician notes are pulled from the document. AI-powered systems use NLP and Computer Vision to accurately locate, interpret, and extract data, even from handwritten or semi-structured content.
5. Validation and Cross-Referencing
To maintain data integrity, logic checks and business rules are applied. For example, if a birthdate appears after a procedure date, the system flags an error. Fields are cross-verified against existing EHR databases or internal logic to catch inconsistencies before final submission.
6. Output Structuring and Integration
Finally, the extracted and validated data are converted into standardized, structured formats. This output is pushed into EHR systems, claims processing software, analytics dashboards, or hospital management systems, ready for action without additional rework.
With the right tools, data extraction in the healthcare sector evolves from a bottleneck into a strategic advantage.
AI-Powered Innovations in Healthcare Data Extraction
AI is not just a trend in healthcare; it’s a transformation engine. When it comes to data extraction in the healthcare sector, AI is making things possible that traditional systems can’t match.
- Natural Language Processing (NLP) understands clinical language. It picks up on context, decodes abbreviations, and distinguishes between meanings like “discharge” as a symptom vs. “discharge” from the hospital.
- Computer Vision helps interpret scanned forms, handwritten notes, and diagrams. It identifies patterns that a human or rule-based engine might miss.
- Self-learning systems adapt to corrections over time. Every time a human reviews a field and adjusts it, the model gets smarter.
AI systems reduce the need for templates or rule-chaining. Instead, they handle semi-structured and unstructured documents natively. This allows real-time integration with EHRs and decision-support systems, empowering physicians and operations staff alike.
Best Practices for Healthcare Data Extraction: Do’s and Don’ts
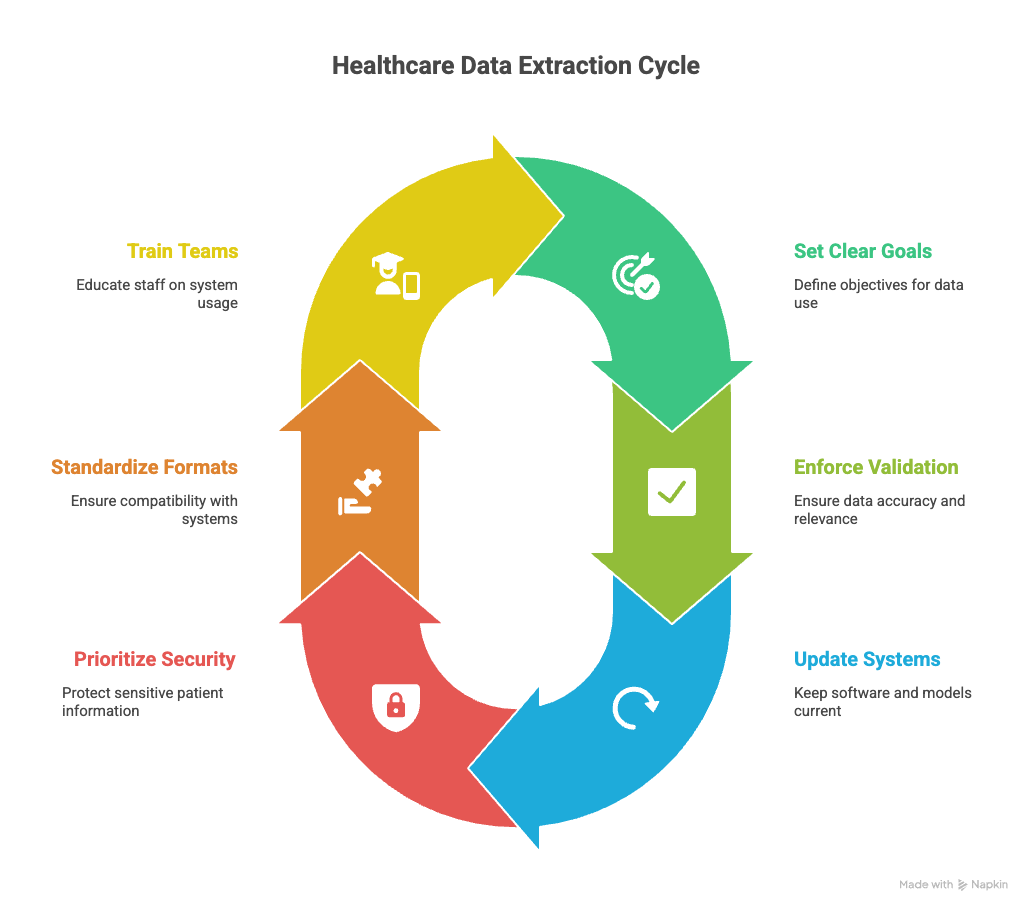
Extracting healthcare data effectively requires more than technology; it takes strategy. By following proven practices, organizations can boost accuracy, protect patient information, and make extracted data usable across systems.
- Set Clear Extraction Goals
Know exactly what you want from the data: claims processing, patient care insights, or research. Clear goals prevent wasted effort. - Enforce Clinical-Grade Validation
Use validation rules that reflect real-world healthcare logic. This ensures extracted data is both correct and clinically meaningful. - Keep Systems Current
Regularly update extraction software and models to support new codes (ICD, CPT) and standards (HL7, FHIR). - Prioritize Security and Compliance
Healthcare data is highly sensitive. Follow HIPAA, GDPR, and other regulations to secure patient information. - Standardize Formats for Integration
Deliver outputs in consistent, structured formats that fit directly into EHRs, claims systems, and analytics tools. - Train Teams for Adoption
Ensure staff understand how to use the system, when to step in, and how to get value from extracted data.
Quick Scan: Do’s vs. Don’ts
Benefits of Data Extraction in the Healthcare Sector
Let’s talk value. When data extraction in the healthcare sector is done right, everyone benefits:
- Faster Operations: Automates manual entry, cuts turnaround time for billing, patient intake, and report generation.
- Higher Accuracy: Reduces the chance of human errors, whether it’s reading a lab value or interpreting a referral.
- Cost Efficiency: Saves labor hours and reduces rework, claim denials, and audit penalties.
- Better Compliance: Extraction tools maintain detailed audit trails and role-based access controls.
- Stronger Analytics: Clean data leads to better dashboards, KPIs, and predictive insights.
- Improved Experience: Less time spent on data entry means more time for patients and planning.
Whether you're a physician, administrator, or data analyst, streamlined extraction helps everyone focus on what really matters.
The Future of Healthcare Data Extraction
Where is all this going?
- Real-Time Intelligence: Systems will flag outliers as they appear, providing early warnings for diagnoses or fraud.
- Embedded Workflows: Extraction won’t be a separate process; it will happen in the background of every system you use.
- Multilingual Capability: As telehealth expands, multilingual understanding will be vital for global care.
- Zero-Touch Correction: Self-correcting engines will use feedback to close the loop without manual review.
- Expanded Interoperability: Extraction tools will speak across platforms, pulling meaning even from legacy systems.
The next decade will not just be about automating tasks. It will be about giving healthcare professionals more clarity, more speed, and more time by letting machines handle the mess behind the scenes.
Bottom Line
The data flood isn’t slowing. And neither can healthcare.
From clinical notes to lab reports to telehealth logs, the industry is awash in valuable information if only it can be accessed and understood. Data extraction in the healthcare sector turns that potential into performance. It reduces risks, accelerates decisions, improves compliance, and saves money.
Whether you're a hospital executive, a software builder, or a provider in the trenches, investing in smarter data extraction isn’t just a technical upgrade; it’s a strategic one. And in the fast-changing world of healthcare, strategy is survival.
The future of care is intelligent. And intelligence begins with the right usage of data, in the right place, at the right time.
Book a demo to see how Infrrd can help your team turn unstructured healthcare data into real-time insight.

Bhavika Bhatia is a Product Copywriter at Infrrd who blends curiosity with clarity to craft content that makes complex tech feel simple and human. With a background in philosophy and a knack for storytelling, she turns big ideas into meaningful narratives. Outside of work, you’ll find her chasing the perfect café corner, binge-watching a new series, or lost in a book that sparks more questions than answers





