
Deep learning is an emerging subset of artificial intelligence in which systems are developed to learn from observation and make decisions without human intervention.
Deep learning systems seek logical patterns in unstructured and uncategorized data sets and, as we saw in How Artificial Intelligence And Deep Learning Algorithms Deliver OCR Accuracy for Business, has powerful applications in optical character recognition (OCR) conversions.
OCR Quiz:
By mimicking the human brain’s recognition and recall faculties, deep learning technology enhances the accuracy of OCR conversions and helps generate insights from the extracted text.
Let’s now look at the conversion process more closely, and specifically see how deep learning helps in the preprocessing of images.
OCR vs. OCR+ML vs. IDP
OCR has inherent limitations when used to extract data from unstructured documents and images. The addition of ML as a preprocessing step helps, but is not sufficient. A better approach is termed Intelligent Data Processing (IDP) which is a template-free, AI-driven approach that is well suited to complex document extraction.

OCR Technology
OCR technology has been in use for a long time to extract text from scanned documents and images to an editable, machine-readable form. The output scanned document is a file that you can edit in Word, not a jpg.
This text recognition delivers significant savings of time, effort, and cost over manual reading and data entry. Many OCR applications today include add-on functionality to recognize some page attributes such as simple tabular structures, fonts, and paragraph styles.
How does OCR work?
The image to be extracted is presented to the final step using a well-defined template. The template tells the OCR to extract the data in a particular, stationary location on the document. Through this process, OCR converts an image into text.
The Importance of Image Quality in OCR Extraction
The success and accuracy of OCR conversion systems are a function of the algorithm used, the quality of the image, and other considerations. While OCR engines are very mature and stable technology, we also need technologies that can improve the quality of images to yield better OCR results.

Images we want to process may have a range of problems such as:
- Image is blurred
- Image lacks contrast
- Scan is skewed
- Scan is warped
- Scan is fuzzy
- Text not aligned in the original document
- itself could have text that is not properly aligned
- Page background may be smudged or muddled
- And more
Such image imperfections will introduce errors in the conversion process and lead to a loss of accuracy.
For this reason, image preprocessing is an extremely important part of the process.
Traditionally, some preprocessing was done manually, prior to attempting the OCR step. Then rules-based software applications that had the ability to do some preprocessing became available.
Now we see deep learning applications being used to handle image preprocessing.
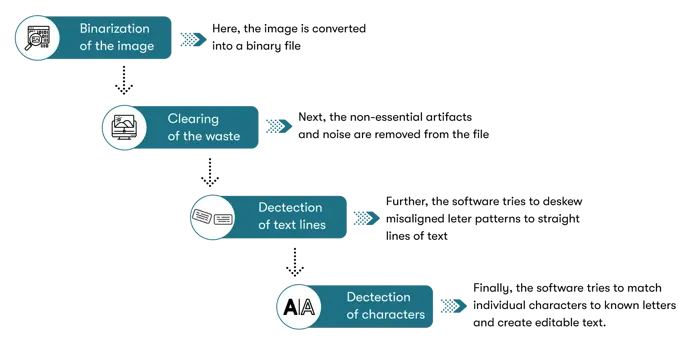
What is OCR Preprocessing?
Image preprocessing works to normalize the content and exclude variations that would reduce the likelihood of text recognition. The steps in preprocessing could include:






