
Gartner recently released, “Infographic: Understand Intelligent Document Processing”. According to Gartner, “The market for document capture, extraction, and processing is highly fragmented. Data and analytics leaders should use this research to understand the process flow and differentiated capabilities offered by intelligent document processing solutions.” In this series of posts, we speak to the 6 critical flows in Intelligent Document Processing (IDP) that Gartner covers and how Infrrd solutions stack up.
1. Capture or Ingestion
2. Document Preprocessing
3. Document Classification
4. Data Extraction
5. Validation and Feedback Loop
6. Integration
In this third post, we explore Data Extraction. (Check out our earlier posts in this series, Capture and Preprocessing and Document Classification.)
Gartner hat kürzlich veröffentlicht,“Infografik: Intelligente Dokumentenverarbeitung verstehen“. Laut Gartner „ist der Markt für die Erfassung, Extraktion und Verarbeitung von Dokumenten stark fragmentiert. Führende Unternehmen aus den Bereichen Daten und Analytik sollten diese Untersuchungen nutzen, um den Prozessablauf und die differenzierten Funktionen zu verstehen, die von intelligente Dokumentenverarbeitung Lösungen.“ In dieser Reihe von Beiträgen sprechen wir über die 6 kritischen Abläufe in Intelligente Dokumentenverarbeitung (IDP), über die Gartner berichtet und wie sich Infrarotlösungen abschneiden.
1. Erfassung oder Aufnahme
2. Vorverarbeitung von Dokumenten
3. Klassifizierung von Dokumenten
4. Datenextraktion
5. Validierungs- und Feedback-Schleife
6. Integration
In diesem dritten Beitrag untersuchen wir Datenextraktion. (Schauen Sie sich unsere früheren Beiträge in dieser Serie an, Erfassung und Vorverarbeitung und Klassifizierung von Dokumenten.)
Warum brauchte die Welt eine neue Datenextraktionslösung?
Wenn Menschen Datenextraktion hören, fällt ihnen normalerweise als Erstes OCR ein. In den letzten Jahren waren traditionelle OCR-Lösungen die bevorzugte Wahl für die Datenextraktion. OCR-Lösungen haben jedoch einige Herausforderungen, da sie sich hauptsächlich auf die Konvertierung von handgeschriebenem oder gedrucktem Text in ein maschinenlesbares, digitales Datenformat konzentrieren.
Die bloße Datenextraktion ohne Informationen, um zu verstehen, was diese Daten aussagen, ist eine enorme Verschwendung von Potenzial. Angesichts des technologischen Wandels profitieren Unternehmen vom Aufkommen neuronaler Netze und Algorithmen für die Verarbeitung natürlicher Sprache oder Computer Vision verwendet in modernen IDP Lösungen.
Hier ist eine Vergleichstabelle zwischen herkömmliches OCR und moderne IDP-Systeme:
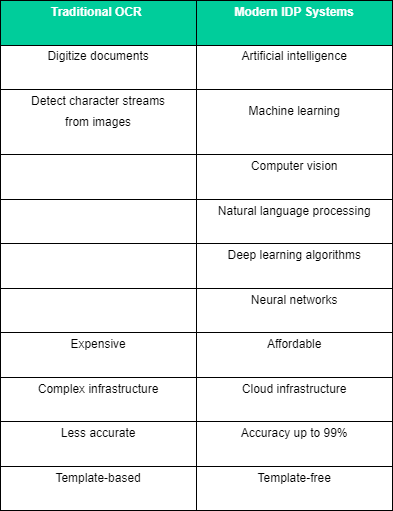
In IDP sind mehrere KI-Technologien wie Natural Language Processing (NLP), Computer Vision und prädiktive Analytik integriert. Die Fähigkeiten des maschinellen Lernens und der KI sind sprunghaft gewachsen und haben die Lücken geschlossen, für die OCR nicht konzipiert war. Moderne IDP-Lösungen verfolgen einen ML-First-Ansatz in Verbindung mit fortschrittlichen KI-Technologien, um relevante und aussagekräftige Informationen aus beliebigen Rohdaten, seien sie unstrukturiert, halbstrukturiert oder strukturiert, nahtlos und mit hoher Genauigkeit zu extrahieren und zu organisieren.
Moderne IDP-Systeme bieten intelligente Datenextraktion und können Millionen von Dokumentvariationen verarbeiten, darunter Rechnungen, Quittungen, Darlehensdokumente und Versicherungsdokumente, ohne Vorlagen zu erstellen. Führende IDP-Anbieter wie Infrrd investieren intensiv und konzentrieren sich auf intelligente Datenextraktion.
In der Vergangenheit waren Unternehmen auf Humanressourcen und Fachwissen angewiesen. Heute ist die Unternehmenswelt auf Datenanalysen angewiesen, um bessere Geschäftseinblicke zu gewinnen, was bedeutet, dass intelligente Datenextraktion automatisch zu einem Schlüsselfaktor für ein Unternehmen wird.
Was bietet IDP?
Ein effizienter IDP-Lösung behebt mehrere Herausforderungen bei der Datenextraktion. Die größte Herausforderung besteht darin, aussagekräftige Daten aus verschiedenen Arten von Informationen wie folgt zu extrahieren:
1. Extraktion von Textdaten
- a. Schlüsselwertpaare
- b. Anerkennung der Entität
- c. Fragen und Antworten
2. Visuelle Datenextraktion
- a. Tabellen
- b. Checkboxen
- c. Logos
- d. Signaturen
- e. Grafiken und Schaubilder
IDP kann hochwertige Daten für Ihr Unternehmen sowohl aus textuellen als auch aus visuellen Elementen des Dokuments extrahieren. Dies ist ein großes Unterscheidungsmerkmal zwischen OCR- und IDP-Systemen. OCRs sind nicht für die Verarbeitung visueller Elemente konzipiert, aber IDP-Systeme werden von Grund auf mit dem Ziel entwickelt, beide Arten von Inhalten zu verarbeiten. Die Plattform von Infrrd nutzt maschinelles Lernen, Deep Learning, Computer Vision und NLP, um Daten aus diesen beiden Inhaltstypen zu extrahieren.
Lassen Sie uns als Nächstes besprechen, wie Daten für diese Inhaltstypen extrahiert werden.
Extraktion von Textdaten
Textdaten in einem Dokument werden mithilfe von Entitätsextraktionsmodellen verarbeitet, einem maschinellen Lernansatz zur Erkennung verschiedener Entitäten in einem Dokument auf der Grundlage Tausender anderer Dokumente, die das System in der Vergangenheit gesehen hat. Diese Modelle identifizieren und trennen eine Reihe von Informationen auf der Grundlage ähnlicher oder gemeinsamer semantischer Parameter. Bei der Entitätenextraktion wird eine Kombination aus zugrundeliegenden Methoden und Technologien verwendet, die vom Verständnis visueller Layouts bis hin zu tiefen neuronalen Netzwerken reichen. Ein effizientes oder trainiertes IDP-System kann ein hohes Maß an Genauigkeit bieten, was die menschliche Leistungsfähigkeit in Frage stellen kann.
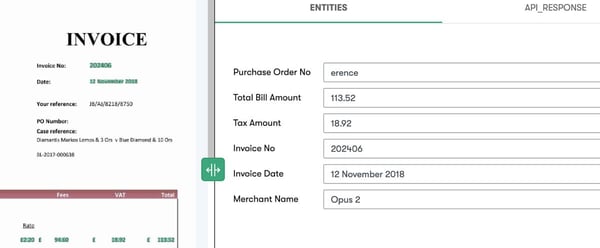
Die Extraktion von Entitäten ist der Schlüssel, um sicherzustellen, dass Sie über eine vorlagenfreie Lösung verfügen, die für eine Vielzahl von Dokumenten funktioniert.
Visuelle Elementerkennung
IDP-Lösungen sind auch geschickt darin, visuelle Elemente wie Tabellen, Checkboxen, Logos und Signaturen zu verstehen. Das Extrahieren von Informationen aus visuellen Elementen ist ziemlich komplex und bringt einige Herausforderungen mit sich, wie zum Beispiel:
- Denoising irrelevanter Inhalte
- Präzises Erfassen des Bereichs, in dem das visuelle Element vorhanden ist
- Erkennung von Elementen mit mehreren Strukturen, Layouts und meist unterschiedlichen Variationen
- Die genauen Grenzen erkennen
- Erkennung von Unterelementen im Interessenbereich und Extrahieren von Informationen aus ihnen, z. B. Zeilen und Spalten für Tabellen
- Segmentierung auf der Grundlage von Semantik
- Entschlüsselung der strukturellen Beziehung der Informationen
Die IDP-Lösung von Infrrd verfügt bereits über eine hochmoderne Funktion zur Extraktion visueller Elemente, die KI-basierte Technologien wie Deep Learning, neuronale Netzwerke und Computer Vision verwendet, um Algorithmen für maschinelles Lernen zu trainieren. Visuelle Elementerkennung und -extraktion sind nur dann von Vorteil, wenn sie genau, effektiv und kognitiv sind und gleichzeitig mehrere, unterschiedliche Variationen verarbeiten.
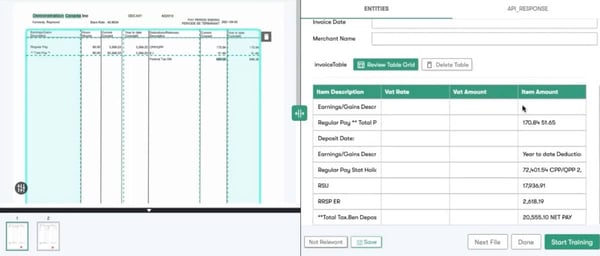
Referenz: Visuelle Elementerkennung: Tabellen
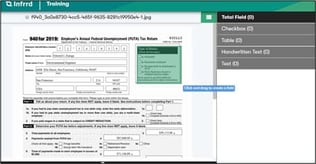
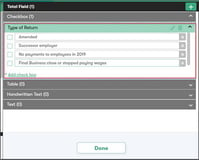
Referenz: Visuelle Elementerkennung: Checkboxen
Die Wahl einer IDP-Plattform, die sowohl Text- als auch visuelle Elemente verarbeiten kann, ist entscheidend, um sicherzustellen, dass Ihr Team keine Dokumente zur Überprüfung öffnen muss. Es erhöht auch Ihre Straight-Through-Processing-Quote.
In unserem nächsten Beitrag untersuchen wir Gartners Beschreibung von Validierungs- und Feedback-Schleife und wie Infrarot abschneidet.

Häufig gestellte Fragen
Software zur Überprüfung und Prüfung von Hypotheken ist ein Sammelbegriff für Tools zur Automatisierung und Rationalisierung des Prozesses der Kreditbewertung. Es hilft Finanzinstituten dabei, die Qualität, die Einhaltung der Vorschriften und das Risiko von Krediten zu beurteilen, indem sie Kreditdaten, Dokumente und Kreditnehmerinformationen analysiert. Diese Software stellt sicher, dass Kredite den regulatorischen Standards entsprechen, reduziert das Fehlerrisiko und beschleunigt den Überprüfungsprozess, wodurch er effizienter und genauer wird.
IDP verarbeitet effizient sowohl strukturierte als auch unstrukturierte Daten, sodass Unternehmen relevante Informationen aus verschiedenen Dokumenttypen nahtlos extrahieren können.
KI verwendet Mustererkennung und Natural Language Processing (NLP), um Dokumente genauer zu klassifizieren, selbst bei unstrukturierten oder halbstrukturierten Daten.
IDP nutzt KI-gestützte Validierungstechniken, um sicherzustellen, dass die extrahierten Daten korrekt sind, wodurch menschliche Fehler reduziert und die allgemeine Datenqualität verbessert wird.
IDP (Intelligent Document Processing) verbessert die Audit-QC, indem es automatisch Daten aus Kreditakten und Dokumenten extrahiert und analysiert und so Genauigkeit, Konformität und Qualität gewährleistet. Es optimiert den Überprüfungsprozess, reduziert Fehler und stellt sicher, dass die gesamte Dokumentation den behördlichen Standards und Unternehmensrichtlinien entspricht, wodurch Audits effizienter und zuverlässiger werden.
Wählen Sie eine Software, die fortschrittliche Automatisierungstechnologie für effiziente Audits, leistungsstarke Compliance-Funktionen, anpassbare Audit-Trails und Berichte in Echtzeit bietet. Stellen Sie sicher, dass sie sich gut in Ihre vorhandenen Systeme integrieren lässt und Skalierbarkeit, zuverlässigen Kundensupport und positive Nutzerbewertungen bietet.





