
Over the past 15 years, I have had the chance to work with many OCR tools and one thing I can say with certainty is that the text extraction quality of these tools has steadily improved with ongoing improvements in artificial intelligence and machine learning OCR techniques.
More than ever businesses are trying to derive useful insights and meaning from scanned images and documents. For example, banks are wanting to extract intelligence such as parties involved and contract expiry dates from scanned contracts, insurance companies are wanting to detect fraudulent receipts submitted during the claims process and many more. Use cases like these require unstructured text be converted into structured meaningful data during OCR or post OCR.
In den letzten 15 Jahren hatte ich die Gelegenheit, mit vielen zusammenzuarbeiten OCR Tools und eine Sache, die ich mit Sicherheit sagen kann, ist, dass sich die Qualität der Textextraktion dieser Tools durch kontinuierliche Verbesserungen der OCR-Techniken für künstliche Intelligenz und maschinelles Lernen stetig verbessert hat.
Mehr denn je versuchen Unternehmen, aus gescannten Bildern und Dokumenten nützliche Erkenntnisse und Bedeutungen abzuleiten. Banken wollen beispielsweise Informationen über die beteiligten Parteien und das Ablaufdatum von Verträgen aus gescannten Verträgen extrahieren, Versicherungsunternehmen wollen betrügerische Belege erkennen, die während des Schadensprozesses eingereicht wurden, und vieles mehr. In solchen Anwendungsfällen muss unstrukturierter Text während oder nach der OCR in strukturierte, aussagekräftige Daten umgewandelt werden.
OCR-Tools verfügen von Natur aus nicht über die Intelligenz, um extrahierten Text zu analysieren oder zu verstehen, als ihn nur zu extrahieren. Um dem Inhalt Bedeutung und Struktur zuzuweisen, muss ein anderes System den extrahierten Text verarbeiten und daraus Entitäten und Entitätstypen extrahieren.

In diesem Beispiel führt das OCR-System eine genaue Textextraktion durch, verfügt jedoch nicht über die Intelligenz, um die Einzelheiten des Händlernamens, der Händleradresse oder anderer wichtiger Details wie Steuern, Gesamtbetrag und einzelne Einzelposten zu identifizieren.
In diesem Artikel möchte ich zwei Techniken zur Textanreicherung nach der OCR vergleichen. Eine ist die konventionelle Technik der Verwendung von Vorlagen, während die andere der moderne Ansatz der Anwendung von maschinellem Lernen ist.
Lassen Sie uns zuerst in die Vorlagen eintauchen. Vorlagen sind, was der Name schon sagt, Vorlagen. Bei dieser Methode markiert der Benutzer manuell Koordinaten für den gewünschten Text auf dem Bild und verwendet anschließend die Ausgabe der OCR-Engine, um Text zu lokalisieren und zu extrahieren. Dieser Ansatz funktioniert gut und ist sehr genau, wenn das Textlayout im gescannten Bild mit dem in der Vorlage codierten Layout übereinstimmt.
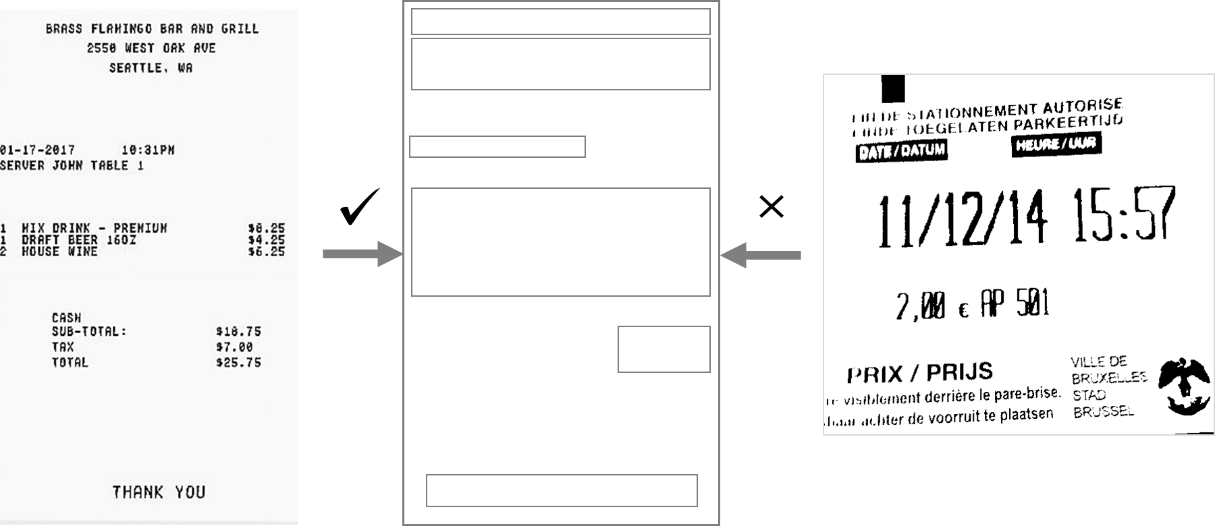
Dieser Ansatz beginnt jedoch bei Systemen, die mit einer großen Anzahl von Dokumentlayouts umgehen, und bei Systemen, die häufig auf neue Dokumenttypen stoßen, zu scheitern. Und Rechnungsverarbeitungssystem das neue Arten von Rechnungen von verschiedenen Lieferanten erhält, ist ein gutes Beispiel. Für einen Bearbeitung von Rechnungen System, ein Vorlagenansatz mag anfangs gut funktionieren, wird aber bald unüberschaubar werden, wenn die Anzahl der Lieferanten wächst und sich ändert.
Betrachten wir nun den alternativen Ansatz des maschinellen Lernens. EIN maschinelles Lernen OCR verwendet ein trainiertes Modell, das Tausende von Regeln kodiert, um die Bedeutung des Inhalts zu bestimmen. Dieses Modell wird in der Regel mit einer Kombination aus überwachten und unüberwachten Lernmethoden trainiert. Ein Trainingsansatz könnte beispielsweise darin bestehen, anhand des folgenden Merkmalsdatensatzes vorherzusagen, ob eine Zeile im Text einen Händlernamen enthält.
Ein trainiertes Modell kann sich selbst optimieren, wenn mehr Trainingsdaten gesammelt und in den Trainingsprozess aufgenommen werden. Der Ansatz des maschinellen Lernens ist für verschiedene Sprachen und Dokumenttypen viel besser skalierbar, auch wenn diese nicht vom System verarbeitet werden. Dieser Ansatz erfordert zwar den anfänglichen Aufwand, qualitativ hochwertige Trainingsmodelle und Modelle zur Erkennung von Entitäten zu erstellen, aber einmal entwickelt, skaliert dieser Ansatz schneller und besser als der Vorlagenansatz.
Bei Infrrd forschen und experimentieren wir mit verschiedenen Techniken, die maschinelles Lernen beinhalten, um die Inhaltsanreicherung nach der OCR-Textraktion aus verschiedenen Dokumenttypen wie Quittungen, Rechnungen, Verträgen und Versandetiketten zu verbessern.

Häufig gestellte Fragen
Software zur Überprüfung und Prüfung von Hypotheken ist ein Sammelbegriff für Tools zur Automatisierung und Rationalisierung des Prozesses der Kreditbewertung. Es hilft Finanzinstituten dabei, die Qualität, die Einhaltung der Vorschriften und das Risiko von Krediten zu beurteilen, indem sie Kreditdaten, Dokumente und Kreditnehmerinformationen analysiert. Diese Software stellt sicher, dass Kredite den regulatorischen Standards entsprechen, reduziert das Fehlerrisiko und beschleunigt den Überprüfungsprozess, wodurch er effizienter und genauer wird.
IDP verarbeitet effizient sowohl strukturierte als auch unstrukturierte Daten, sodass Unternehmen relevante Informationen aus verschiedenen Dokumenttypen nahtlos extrahieren können.
KI verwendet Mustererkennung und Natural Language Processing (NLP), um Dokumente genauer zu klassifizieren, selbst bei unstrukturierten oder halbstrukturierten Daten.
IDP nutzt KI-gestützte Validierungstechniken, um sicherzustellen, dass die extrahierten Daten korrekt sind, wodurch menschliche Fehler reduziert und die allgemeine Datenqualität verbessert wird.
IDP (Intelligent Document Processing) verbessert die Audit-QC, indem es automatisch Daten aus Kreditakten und Dokumenten extrahiert und analysiert und so Genauigkeit, Konformität und Qualität gewährleistet. Es optimiert den Überprüfungsprozess, reduziert Fehler und stellt sicher, dass die gesamte Dokumentation den behördlichen Standards und Unternehmensrichtlinien entspricht, wodurch Audits effizienter und zuverlässiger werden.
Wählen Sie eine Software, die fortschrittliche Automatisierungstechnologie für effiziente Audits, leistungsstarke Compliance-Funktionen, anpassbare Audit-Trails und Berichte in Echtzeit bietet. Stellen Sie sicher, dass sie sich gut in Ihre vorhandenen Systeme integrieren lässt und Skalierbarkeit, zuverlässigen Kundensupport und positive Nutzerbewertungen bietet.





