

Ready to get started?
See our platform in action to experience the transformative efficiencies it can bring to your processes


With a dedicated research team working on creating high-end machine learning algorithms, Infrrd’s extraction feature is like no other in the industry. The data you need from a particular document type may be the same but the individual documents could be laid out in a million different ways. Automatically extract high-value data from text and visual elements. It enables accurate, effective, and cognitive extraction even while handling multiple, diverse variations.
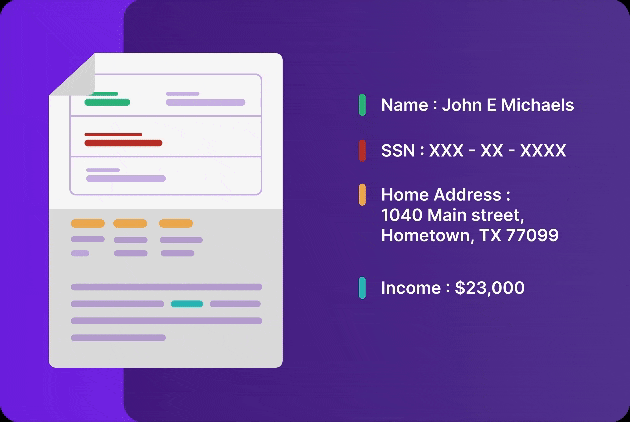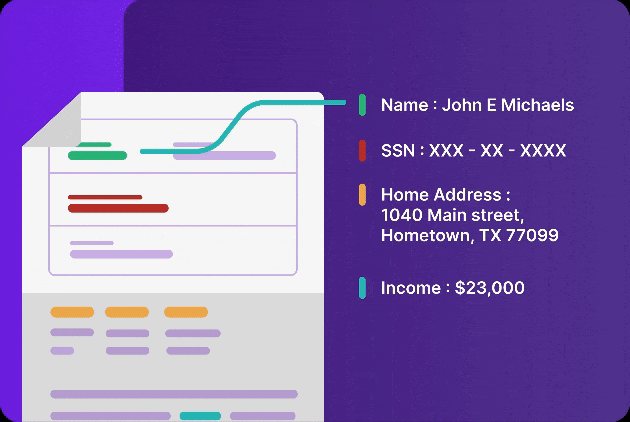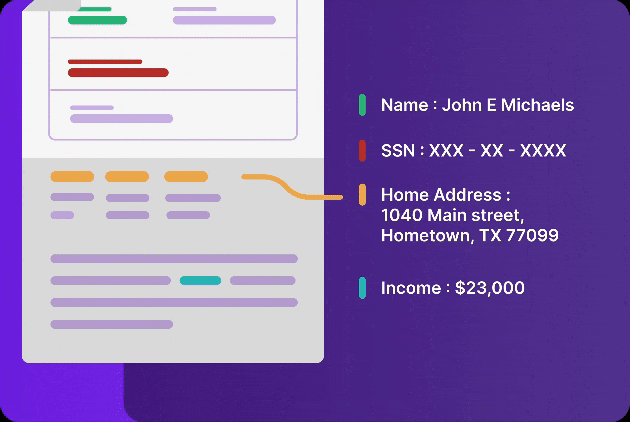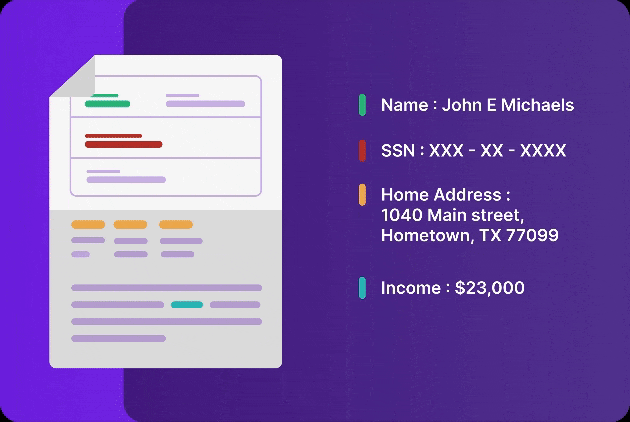
Like a human-eye, Infrrd’s extract capability automatically detects where visual elements such as tables, logos, checkboxes and signatures are present and extracts data from them accurately.
Infrrd NLP research that powers our extraction engine has been recognized in the academic research circle. Recently, their research methodology which is now a part of our product won the first place in Natural Language for Optimization (NL4Opt) 2022 competition

In this Garter report series, dig deeper into the steps of IDP to document extraction
See our platform in action to experience the transformative efficiencies it can bring to your processes

